Introduction to Machine Learning - Regression Models
https://ubc-library-rc.github.io/ml-regression/
0:05 - 0:15 About Machine Learning
0:15 - 0:30 About Regression
0:30 - 1:20 Hands-on with Jupyter Notebook
1:20 - 1:30 Wrap-up and Discussion
Land Acknowledgement
UBC Vancouver is located on the traditional, ancestral, and unceded territory of the xʷməθkʷəy̓əm
(Musqueam)
peoples.
Use the Zoom toolbar to engage
Participants window
Active participation makes the session so much fun and gives me and your peers much more energy.
We are
all sitting in our offices with little sound. Your voices and perspectives enlivens the session.
We encourage
you to engage with each other and instructors.
The participants window lists everyone in the session and click the icons at the bottom to
communicate with
the instructors.
You can also use the Chat windows to comment or ask questions at any time. It is also a good
place to share
problems with your audio connection.
CCDHHN Certificate
This workshop contributes towards the Canadian Certificate in Digital Humanities.
This workshops is eligible for the Canadian Certificate in Digital Humanities
https://ccdhhn.ca/. This is a
program that allows you to claim non-credit workshops and training towards a certificate. If you
are
interested in claiming this workshop please fill out this form:
https://ubc.ca1.qualtrics.com/jfe/form/SV_cwiqRxedypNPhA2. This is how we track attendance for
the purposes
of the certificate, it will only be shared during the workshop and will not be emailed to you
after."
Note that they have to click on the form during the workshop, we will not share it after. If you
could
encourage anyone who's interested to take a few minutes and fill it out at the end of the
workshop that
would be great.
Learning Objectives
Understand regression models and their applications in
machine
learning
Train regression models for real-world datasets
Interpret and analyze regression model results.
So, to touch various viewpoints of machine learning regression, we have the following learning
objectives
for this workshop:
Pre-workshop setup
For hands-on exercises, we will use [Python](https://www.python.org/) on [Jupyter
Notebooks](https://jupyter.org/). You don’t need to have Python installed. Please make sure that
you have a
[UBC Syzygy](https://ubc.syzygy.ca/) or a [Google
Colaboratory](https://colab.research.google.com/) account.
(You will need a CWL login to access Syzygy.)
hands-on exercises, programming tools and libraries, such as [Python] and [scikit-learn] prior
familiarity
with Python programming is recommended, we do not study the codes in detail
What is Machine Learning?
“Field of study that gives computers the capability to
learn without
being explicitly programmed" - Arthur Samuel
What comes to your mind when you hear of the word machine learning?
field of computer science, teaching computers to learn from data, without explicitly defining
the rules
applicable to the problem.
algorithms or mathematical models trained large datasets to recognize pattern
Replace the question mark
X
Y
1
2.2
2
4.8
3
7.1
4
?
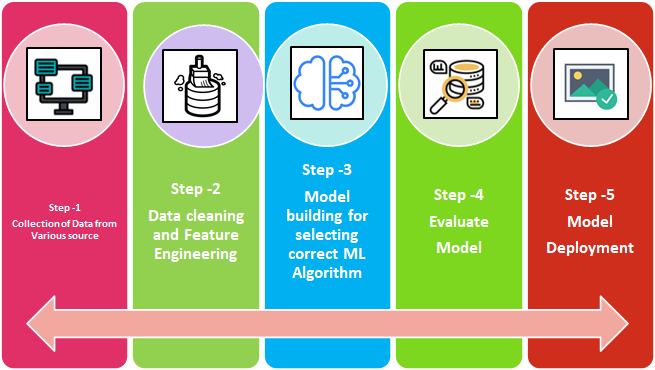
Building a Machine Learning Model
- **Data Collection:**: gathering and preparing data, he quality of the data used in the model
directly impacts
its accuracy and effectiveness
- **Data Preprocessing:** cleaned, transformed, and formatted into a suitable format
- **Model Training:** Once the data is ready, it is used to train a machine learning model.
- **Model Evaluation:** After the model has been trained, it needs to be evaluated to ensure that it
is
performing accurately. This is done using a test set of data that was not used during the training
process.
- **Model Deployment:** Once the model has been trained and evaluated, it can be deployed for use in
a
production environment. This involves integrating the model into a larger system and ensuring that
it can handle
real-world data. This step involves choosing a suitable employment platform.
- **Model Improvement:** Machine learning is an iterative process, so the model may need to be
improved over
time. This can involve retraining or fine-tuning its parametersthe with new data or continues stream
of data.
Types of Machine Learning
From javatpoint
Some other types:
Reinforcement Learning
Transfer Learning
There are different types of machine learning, including supervised learning, unsupervised learning,
and
reinforcement learning, each with its own set of algorithms and techniques.
* Supervised Learning:
an algorithm is trained on a labeled dataset, meaning that the dataset has input features (X) and
corresponding
output labels (Y). The goal of supervised learning is to learn a function that maps the input
features to the
output labels. Once the model is trained, it can be used to make predictions on new data. Examples
of supervised
learning tasks include image classification, speech recognition, and regression analysis.
* Unsupervised Learning:
Unsupervised learning is a type of machine learning where the algorithm is trained on an unlabeled
dataset,
meaning that there are no output labels (Y) associated with the input features (X). The goal of
unsupervised
learning is to learn patterns and structure in the data without the help of a labeled dataset.
Examples of
unsupervised learning tasks include clustering, anomaly detection, and dimensionality reduction.
* Reinforcement Learning:
Reinforcement learning is a type of machine learning that involves an agent interacting with an
environment to
learn how to make decisions that maximize a reward. The agent receives feedback from the environment
in the form
of rewards or penalties, and its goal is to learn a policy that maximizes the expected long-term
reward.
Reinforcement learning is often used in robotics, game playing, and control systems.
* Transfer Learning:
Transfer learning refers to a technique in which a pre-trained model, typically trained on a large
dataset, is
used as a starting point for training a new model on a smaller dataset or a different but related
task. The idea
is that the knowledge learned from the pre-trained model can be transferred to the new task,
allowing the new
model to start with some level of knowledge or "transfer" from the previous task, which can
potentially improve
its performance and reduce the amount of training data required.
Methods and Algorithms
In this section, we will provide an overview of these three machine learning algorithms, discuss
their strengths
and weaknesses, and provide examples of their applications.
Data Preparations
Types of Features (continuous/categorical)
Handling missing values
Feature scaling
Feature selection
Before going to the main step, it is a good idea to learn a little bit about the steps right before
and after
the model training step
Continuous vs Categorical Variables
Handling missing values - drop, impute, forward backward fill
Feature scaling: standardization, min-max scaling, Feature selection
Model Evaluation
From geeksforgeeks
Overfitting underfitting
we look at the measures for model evaluation in the next section as they are specific to the type of
the model
Algorithms and Methods
From mathworks
Algorithms and Methods
From mathworks
Python Libraries
Numpy: NumPy is a library for the Python programming language, adding support for large,
multi-dimensional
arrays and matrices, along with a large collection of high-level mathematical functions to operate
on these
arrays.
Pandas: pandas is a software library written for the Python programming language for data
manipulation and
analysis. In particular, it offers data structures and operations for manipulating numerical tables
and time
series.
Matplotlib: Matplotlib is a plotting library for the Python programming language and its numerical
mathematics
extension NumPy.
scikit-learn is a free software machine learning library for the Python programming language.
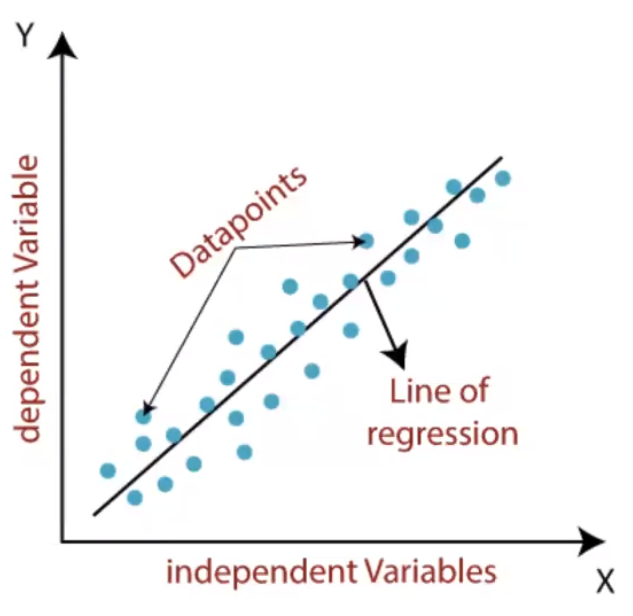
Regression
From Javatpoint.com
Regression is a type of supervised machine learning algorithm used to predict a continuous numerical
outcome
variable based on one or more predictor variables. In regression analysis, the goal is to establish
a
relationship between the predictor variables and the outcome variable, which can then be used to
make
predictions on new data.
Linear, logistic, polynomial regression
First example and regression metrics at the end
Limits of Machine Learning
Garbage In = Garbage Out
Data Limitation
Generalization and overfitting
Inability to explain answers
Ethics and Bias Limitations
Computational Limitations
Some of the differentiation factors of machine learning models also count as their limits:
* Garbage In = Garbage Out
In machine learning, the quality of the output model is directly dependent on the quality of the
input data used
to train it. If the input data is incomplete, noisy, or biased, the resulting model may be
inaccurate or
unreliable.
For example, suppose a machine learning model is being developed to predict which loan applications
are likely
to be approved by a bank. If the training dataset only contains loan applications from a particular
demographic
group or geographic region, the resulting model may be biased towards that group or region and may
not
generalize well to other groups or regions. This could lead to discrimination and unfair lending
practices.
* Data Limitation
Machine learning algorithms are only as good as the data they are trained on. If the data is biased,
incomplete,
or noisy, the algorithm may not be able to learn the underlying patterns or may learn incorrect
patterns. Also,
machine learning models require large amounts of labeled data for training, which can be expensive
and
time-consuming to obtain.
* Generalization and overfitting
Machine learning models are typically trained on a specific dataset, and their ability to generalize
to new data
outside of that dataset may be limited. Overfitting can occur if the model is too complex or if it
is trained on
a small dataset, causing it to perform well on the training data but poorly on new data. When a
model is
overfitting, it is essentially memorizing the training data rather than learning the underlying
patterns in the
data.
* Inability to explain answers
Machine learning models can be complex and difficult to interpret, making it challenging to
understand why they
make certain predictions or decisions. This can be a problem in domains such as healthcare or
finance where it
is important to be able to understand the rationale behind a decision.
* Ethics and Bias Limitations
Machine learning algorithms can amplify existing biases in the data they are trained on, leading to
unfair or
discriminatory outcomes. There is a risk of unintended consequences when using machine learning
algorithms in
sensitive areas such as criminal justice, hiring decisions, and loan applications. One example of
bias in
machine learning is in facial recognition technology. Studies have shown that facial recognition
systems are
less accurate in identifying people with darker skin tones and women. This bias can lead to
misidentification,
which can have serious consequences, such as wrongful arrest or discrimination in hiring. In the
context of
healthcare, machine learning algorithms can also perpetuate bias and discrimination. For example, if
the
algorithm is trained on biased data, it may make less accurate predictions for certain demographic
groups, such
as racial minorities or people with disabilities.
* Computational Limitations
Machine learning algorithms can be computationally expensive and require a lot of computing power to
train and
run. This can be a barrier to adoption in applications where real-time or low-power processing is
required. One
example of computational limitations in machine learning is training deep neural networks. Deep
neural networks
are a type of machine learning algorithm that can learn complex patterns in data by using many
layers of
interconnected nodes. However, training these models can be computationally expensive, requiring
significant
computing power and memory.
For example, training a state-of-the-art natural language processing model like BERT (Bidirectional
Encoder
Representations from Transformers) can take weeks or even months on a large cluster of GPUs. This
limits the
ability of smaller organizations or individuals with limited computing resources to develop or use
these models.
Open Jupyter Notebooks
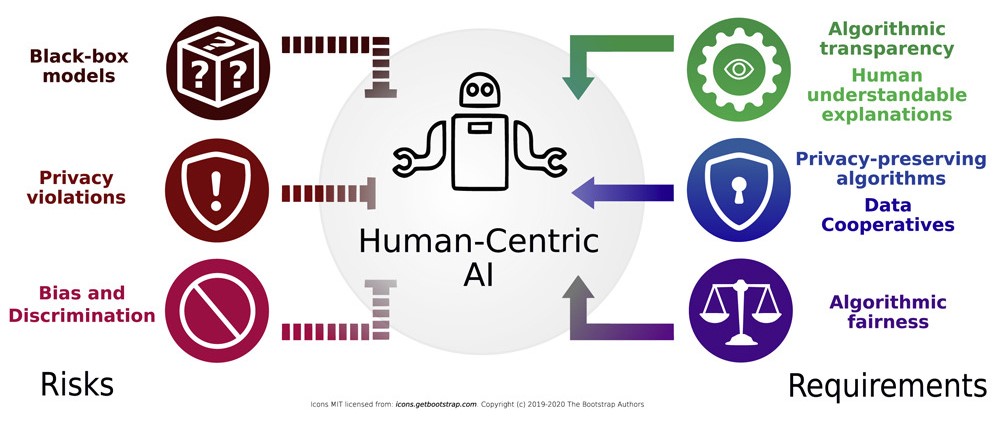
Ethics
Image from: Lepri, Bruno, Nuria Oliver, and Alex Pentland.
"Ethical machines:
The human-centric use of artificial intelligence." IScience 24.3 (2021): 102249.
Future workshops
Title
Series
Regression models
Wed, Mar 11, 2026 (1:30pm to 3:30pm) - Today
Classification and clustering models
Wed, Mar 25, 2026 (1:30pm to 3:30pm)
Neural networks
Wed, Apr 8, 2026 (1:30pm to 3:30pm)
Register
here
More from the Research Commons at (UBC-V)
And from the Center for Scholarly Communication (UBC-O)