The R coding language is similar to English
Code is read from left to right and from the top of the script (line 1) to the bottom of the script.
Note: An R script is a document where you write code that you want saved. This is where you should do your data analysis. When people share R code, they send each other R script files.
This means, that your code needs to be written in the correct order to be able to run it without errors
Just like a book or lab protocol, there is a method to organizing your code. We outline these parts below and then go into what each of these elements are in the following sections.
-
Set up your R session
-
Formatting your data
-
Data analysis.
Set up the R session
R needs some set up and some additional information before it can be expected to interact with data that it needs to analyze.
Set up part 1: Load in packages
Packages are add-ons to R that allow you to use a single command to perform an action, rather than typing a bunch of code. Think of packages like browser extensions. You don’t need browser extensions for your browser to work, but the customization packages offer make the experience of going online much better.
Packages are installed the first time you use them with the install.packages() command. This only needs to be run once per package on your computer.
Every time you want to use the package, you need to load it into R using the library() command. The library() command should be added to your R Script.
# install package
install.packages("tidyverse")
# load package
library(tidyverse)
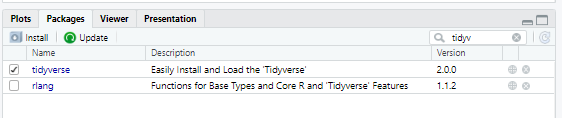
You can also install packages manually from RStudio by clicking the grey install button (top left of image) and start typing the name of the package in the search box that pops up.
Once you have installed a packges, you can check if it’s loaded or not visually by using the search box at the top right of the picture. See how tidyverse has a check mark next to it? That means is tidyverse loaded (we successfully ran the library(tidyverse) command)! See how rlang does not have a check mark next to it, that means it’s installed, but not loaded, so we can’t use any of the commands in rlang right now, but we can use the commands in tidyverse.
What if you search for a package name and it’s not there? Check the spelling and if it’s correct, that means the package is not installed.
Aside: What are #?
A # is the R symbol for a comment. Commenting out a line of code makes it not run. This is useful to make notes about why you did something (organization) or just removing part of your existing code for troubleshooting purposes.
Putting 1 or more # in front of text does the same thing.
# won't run
## same thing as above
############# still the same thing as above
However, if you add at least four # at the end, you can create code sections. This is very helpful because it lets you collapse entire chunks fo code and makes it less overwhelming once your script get very long. The number of # at the start does not matter and it’s okay to have more than four # at the end. I like to put five # on each side of the title for absolutely no reason except I think it looks pretty.
#### section 1 name ####
# section 2 name ####
## section 3 name ####
Set up part 2: Tell R where to get data
Now that R has all the packages we need loaded, we need to tell R where to look for data on your computer. Where R looks for data is called the working directory and can be customized for each RScript you make.
You can set your working directory manually by clicking Session> Set Working Directory > Choose Directory > Navigate to where your data are in your files.
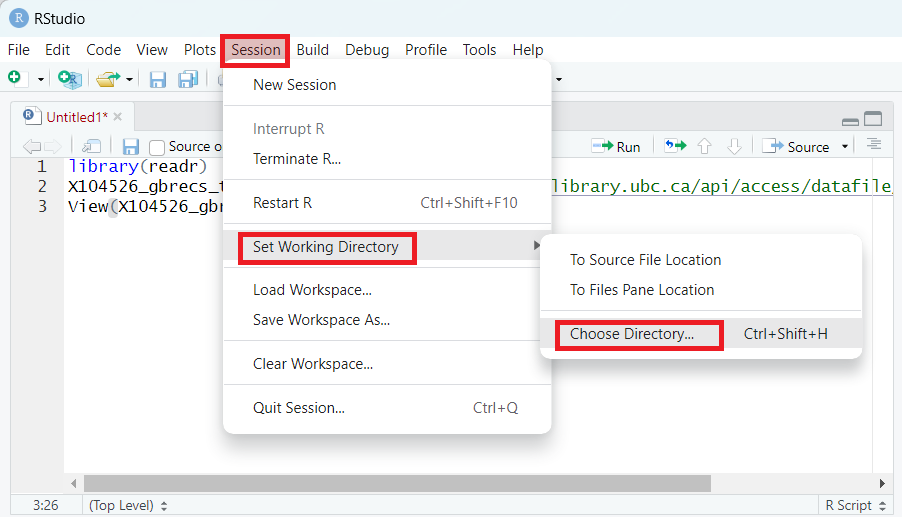
Once you have set your working directory manually like this, you can copy/paste the output from the console and add it to your script.
## set working directory
setwd("C:/Desktop")
# you need to put your own path inside the setwd() backets.
# MAC USERS!! you will have a ~ instead of a C:
Set up part 3: Load in your data
Now that R knows where to look for files, you can read them into R.
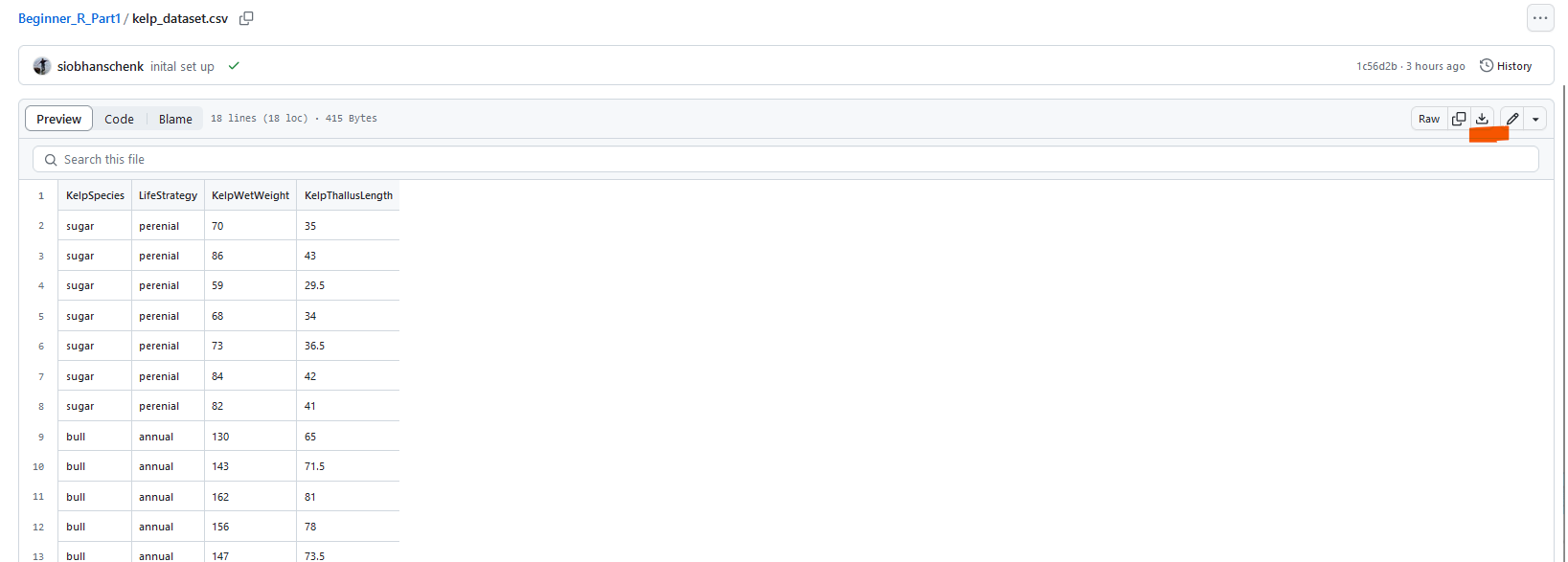
We will use the .csv file linked here for the workshop https://github.com/ubc-library-rc/Beginner_R_Part1/blob/main/kelp_dataset.csv Once you get to the webpage, click on the download button (underlined in orange in the top right of the image below) to download the file.
R can read in a bunch of different files types. some like .csv and .RDS are readable from R without loading packages first. Other files types, like .xlsx and .sav need you to load packages before you can read in the files.
You can do this by typing the correct read file command into your your script or by clicking the import dataset button (image below). If you use the import dataset button, you should copy paste the output from the console in your script so you can just run the script without manually selecting the data every time.

# read in the .csv file
kelp_dataset=read.csv("kelp_dataset.csv")
# note, = and <- are the same. They are both used to assign variables.
# The == is different and means exactly equal to, which is useful to subset data.
Now we see that the dataset is in our Environment, so it’s loaded properly.
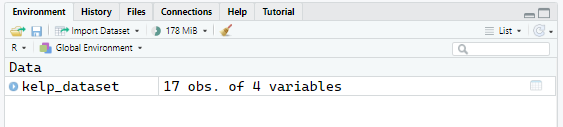
Now, we want to look at our data. We can do this with the View() function
# look at the data
View(kelp_dataset)
If you clock on the name of the dataset in the environment, you can achieve the same effect as View(). However, if you click on the little blue arrow next to the dataset, you will have an overview of what your column headers are called and the variable type of each column.

You can also use the summary() function to get an overview of your data
# see summary (mean, min, max, and other) of all your variables
summary(kelp_dataset)
Format your data
Data that are not formatted properly are the source of many error messages in R. We are not going to go over data formatting today because we have many other workshops to do that.
Overall, in this section, you would clean up your data by removing parts of it you don’t want to analyze, change the variable types, join many datasets together, or manipulate your data in various other ways.
Data Analysis
This section is really what you want to be doing when you open up R and we are finally there! The analysis you do for your own work will likely require the installation of new packages and you will have some troubleshooting to do.
Today, we will go over some of the built in functions that R has for simple data analysis.
Calculate the mean
Run the following line and look for the output in the console
Here, we are telling R, take the KelpWetWeight column in the kelp_dataset and calculate the mean (of the KelpWetWeight column).
mean(kelp_dataset$KelpWetWeight)
# there is also sum(), median(), min(), max(), and a bunch of other similar functions
# here is a webpage with all the base R functions https://rdrr.io/r/
Right above, we put a URL link in a comment. This is a very good habit to have, because you might find a webpage that has answers you are looking for or explains why you did something a particular way. The best spot to store those resources is right next to the relevant code!
Run a correlation test
Lets see if thallus length and weight are correlated. The output for this will also be in the console.
cor.test(kelp_dataset$KelpWetWeight, kelp_dataset$KelpThallusLength)
Lets plot the data we just ran the correlation test on. This output will be in the plot section of RStudio.
plot(kelp_dataset$KelpWetWeight, kelp_dataset$KelpThallusLength)