Basic syntax
In this section, we’ll cover the basic syntax of regular expressions.
Literal characters
The simplest form a regular expression can take is a plain text string without any special characters. This will match each of the literal characters in the string exactly. When reading regular expressions, it’s helpful to read them according to the meaning of each character, not what we usually call the character. For example, tune will match a literal t, a literal u, a literal n, and a literal e. tune will match:
tune
attuned
fortune
inopportune
Matches are case-sensitive by default. For example, the pattern tune represents only the first, lowercase, instance of this word in the following string:
Humming a tune as you work can improve your mood. Tune is another word for song.
In other words, the second instance of “Tune” will not be matched because the T is uppercase, and the search pattern was tune rather than Tune.
If you wanted to find both tune and Tune, you could either turn off case-sensitive matching (see later in this workshop), or use a different pattern, such as [Tt]une to match both the uppercase T and lowercase t in the text. We’ll cover what square brackets mean in a minute.
Any string of letters and/or numbers that doesn’t contain metacharacters will be interpreted literally in a regular expression.
Metacharacters
What are metacharacters, then? They’re characters (or tokens) that have special meaning when used in regular expressions:
| Input | Pattern | Description | Number of Matches | Return |
|---|---|---|---|---|
| Hello World! | . | Period. Matches any single character, except a newline. | 12 | ‘H’, ‘e’, ‘l’, ‘l’, ‘o’, ‘ ‘, ‘W’, ‘o’, ‘r’, ‘l’, ‘d’, ‘!’ |
| Hello World! | lo* | Asterisk. Matches as many of the preceding token as possible (including 0) (greedy). | 3 | ‘l’, ‘lo’, ‘l’ |
| Hello World! | o+ | Plus sign. Matches 1 or more repetitions of the preceding token. | 2 | ‘o’, ‘o’ |
| Hello World! | lo? | Question mark. Matches 0 or 1 of the preceding token (makes the preceding token optional). | 3 | ‘l’, ‘lo’, ‘l’ |
| Hello World? | Hello World\? | Backslash. Escapes the next character. This allows you to make metacharacters become literal characters (for example, ‘\?’ will match a literal question mark). | 1 | ‘Hello World?’ |
| Hello World! | ^World! | Caret. Matches the beginning of a line. | 0 | No match found |
| Hello World! | World!$ | Dollar sign. Matches the end of a line. | 1 | ‘World!’ |
| Hello World! | [aeiou] | Square brackets. Creates a character class. Matches a single character contained between the square brackets. For example, above, we wrote ‘[Tt]une’ which matches for both ‘Tune’ and ‘tune’. | 3 | ‘e’, ‘o’, ‘o’ |
| Hello World! | [^aeiou] | Square brackets with a caret (or circumflex). Creates a negated character class. Matches a single character that is not contained between the square brackets. | 8 | ‘H’, ‘l’, ‘l’, ‘ ‘, ‘W’, ‘r’, ‘l’, ‘d’, ‘!’ |
| Hello World! | [a-z] | Square brackets can also be used for ranges. This range says match any character in the range ‘a-z’. This can also be done with numbers, for example ‘0-9’. | 8 | ‘e’, ‘l’, ‘l’, ‘o’, ‘o’, ‘r’, ‘l’, ‘d’ |
| Hello World! | [^a-z] | Similarly, ranges can be negated as well with a caret/circumflex. | 4 | ‘H’, ‘ ‘, ‘W’, ‘!’ |
| Hello World! | l{1} | Curly braces. This will match exactly x number of the preceding character. For example ‘a{3}’ matches exactly 3 of a. | 3 | ‘l’, ‘l’, ‘l’ |
| Hello World! | l{1,} | Curly braces. This will match n or more times of the preceding character. For example, ‘a{3,}’ will match 3 or more times of a. | 2 | ‘ll’, ‘l’ |
| Hello Worllld! | l{1,3} | Curly braces. These match at least n but not more than m times of the preceding character. For example, ‘{1,3}’ will match at least 1 time but not more than 3 times. | 2 | ‘ll’, ‘lll’ |
| Hello World! | (Hello) | Brackets. Character group. Matches the characters Hello in that exact order. | 1 | ‘Hello’ |
| Hello World! | Hello|World | Pipe. Used for alternation. Matches either the characters before or the characters after the token (if both are found, both will be matched). | 2 | ‘Hello’, ‘World’ |
Metacharacters can be combined, too. For example, . matches any character except a newline, once. .+ will match any character except a newline, as many times as possible, but at least once.
Examples
Example 1
Matching on tune|bag (literal t, u, n, e, and/or (alternation), literal b, a, g):
The garbageman hoisted another heavy bag, whistling a familiar tune as he worked. He was keenly attuned to the rhythm of the city, even at this early hour. However, an inopportune moment arrived when several bagels and a wilted cabbage tumbled from the bag, scattering across the pavement. He chuckled, realizing he didn’t have much fortune this morning.
Example 2
Sometimes American spellings and Canadian spellings of words are mixed up in one text, or perhaps in a search, you’d like to be able to match both versions in one go.
Matching on colou?r|favou?rite (literal c, o, l, o, optional u, literal r, and/or literal f, a, v, o, optional u, literal r, i, t, e):
Lena’s favourite color had always been purple, but the rich green of the forest called to her in a way she couldn’t ignore today. As she sat quietly among the trees, she noticed how the light played with the different colours of the leaves, each one more vibrant than the last. It was in that moment that she decided the forest’s colors would always be her favorite sight, no matter the season.
Example 3
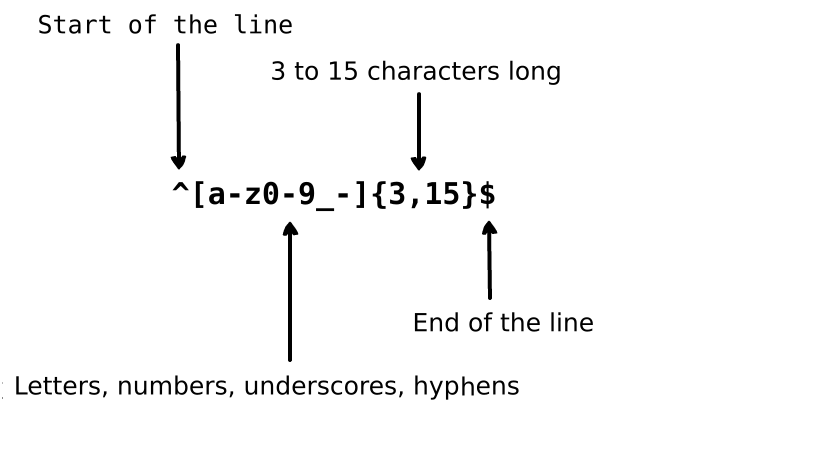 Image from Learn Regex the Easy Way)
Image from Learn Regex the Easy Way)
{kind=link}
This regular expression matches any text that is:
- anchored to the start of a line
- contains any of the letters
a-z, the numbers0-9, underscores, and/or hyphens - 3 to 15 characters long
- anchored at the end of the line
In the following text, this will match:
john_doe
jo-hn_doe
john12_as
but not:
Jo
This is a common regex to search for usernames (though, capital A-Z is often also permitted, but is omitted here). Try out some other possible usernames or phrases to see what matches or doesn’t match.
Loading last updated date...