Concepts and Tools
What is Python and why use it for web scraping?
Python is a high-level, popular programming language that comprises the following features which makes it ideal for web scraping:
- Usability - It is simple to code. You do not have to add semi-colons “;” or curly-braces “{}” anywhere.
- Libraries - Python has a huge collection of libraries such as Numpy, Matlplotlib, Pandas etc., which provides methods and services for various purposes. Hence, it is suitable for web scraping and for further manipulation of extracted data.
- Dynamically typed - In Python, the datatypes for variables can be used without defining them at first hence it is faster.
- Syntax - Python syntax is similar to English, expressive, readable, and the indentation in the code helps to differentiate between different scope/blocks.
- Efficiency - Small codes can execute larger tasks.
- Community - Python community is one of the biggest and most active communities, where you can seek help from if you are stuck at coding.
Python Datatypes
Python has the following data types built-in by default, in these categories:
Text Type: str
Numeric Types: int, float, complex
Sequence Types: list, tuple, range
Mapping Type: dict
Set Types: set, frozenset
Boolean Type: bool
Binary Types: bytes, bytearray, memoryview
None Type: NoneType
Understanding Website Structure
Website content is usually represented using HTML, or Hypertext Markup Language. Web servers make HTML content available to browsers using a data transfer protocol called HTTP (Hypertext Transfer Protocol). Two of the most common HTTP request methods are get (to request data from a server) and post (to send data to a server).
Web scraping tools use a website’s HTML structure to navigate the page and identify the content to scrape. Effective use of web scraping tools requires a basic understanding of how web pages are structured. Sites whose underlying structure is well organized and descriptive are usually easier to scrape.
Using Browser “Inspect” tools
Most browsers have built-in “inspect” tools that allow you to explore the HTML structure of a web page. In most browsers (including Chrome, Firefox, and Edge) right-click any part of a page and select Inspect or Inspect element to open a panel showing how the selected content is represented in the HTML.
In Safari inspect element is not enabled by default.
To enable in Safari go to Preferences -> Advanced and enable Show Developer menu in menu bar.
This screenshot below shows the Inspect tool applied to a web page accessed with Chrome: http://econpy.pythonanywhere.com/ex/001.html. The page is a list of buyer names and item prices.
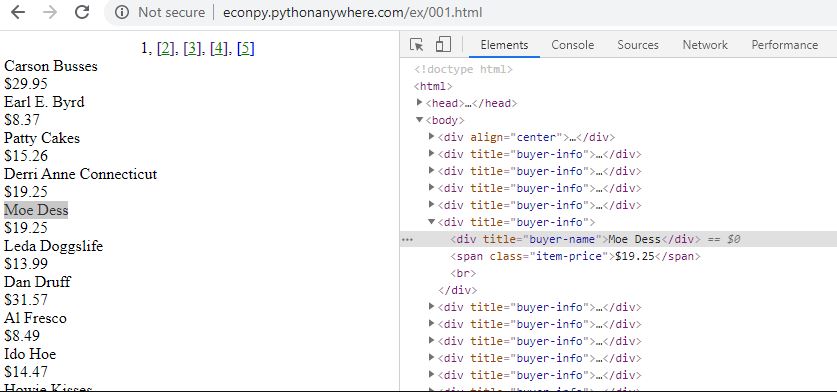
In a simple site like this it is easy to see the correlation between displayed content and HTML elements. You can expand the HTML elements in the inspection window to reveal other content and hover over elements to highlight the corresponding section in the web page.
Web scrapers navigate the HTML structure using XPath, a language that identifies and selects content nodes on the site. In the example above all buyer names are contained in <div> elements like this
<div title="buyer-name">Moe Dess</div>
The XPath expression that identifies all “buyer-name” nodes on the page is
//div[@title="buyer-name"]
Loading last updated date...