How do LLMs work?
To best use a tool, it is critical to understand how it works. In this first workshop of the ChatGPT and Data Analysis series we use non-technical language to explain how Large Language Models (LLMs) like ChatGPT work, so you can use them more effectively.
By the end of this session we hope you will:
- have a conceptual understanding of how LLMs work
- know how to access and engage with ChatGPT
Where is ChatGPT?
ChatGPT is a Large Language Model (LLM) that is available online. Just like any website, you need to be connected to the internet to use it.
Overview of what it means to “train a model”
The library has a detailed workshop about LLMs, so for this workshop we are not going to get very technical. The very simplified version of training a model includes two steps:
- "the computer" looks at a lot of data (training data) to learn the patterns that exist
- "the computer" takes new data that it has never seen before (testing data). Then, using what it learned in step 1, "the computer" sees if it can predict what comes next.
Because LLMs are always improving, “the computer” (the LLM) always goes back to step 1. Your brain is a very fancy LLM in a lot of ways. For example:
- Have you ever finished someone's sentence for them? Does this happen more often when you know the person better?
- Can you tell how people are feeling? Are you much more accurate with people you know better?
That’s right, you are predicting what is going to come next based on previous data (experience with that person). More and better data = better predictions. In addition, humans can rely on more than just “data”, “patterns”, and “predictions” to shape and adjust their behavior. We rely on context around this information to inform our actions.
That's very cool! But, this should cause you to pause. You are also wrong sometimes, even with the people you know best (partners, best friends, kids,...).
LLMs can be wrong too. LLMs can be wrong because the model is wrong and/or because they are missing context. This is a major concern when using LLMs, or any AI tools for that matter.
How to get factually correct answers
In LLM speak, mistakes are often called hallucinations. They occur because the LLM outputs the best answer possible, but has insufficient data to provide a correct answer.
Ask for sources
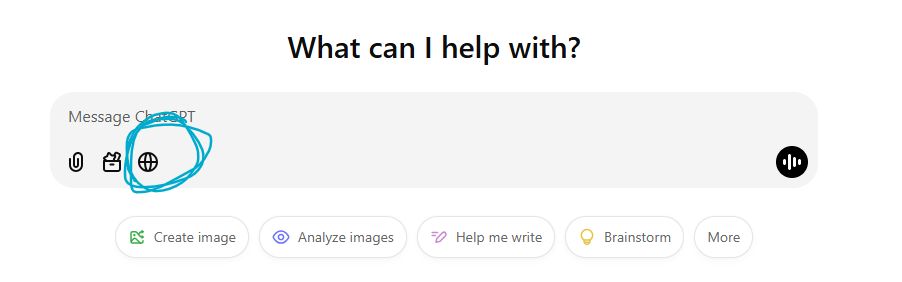
ChatGPT has a way to turn on sources. Click on the globe (circled in blue) before submitting your query.
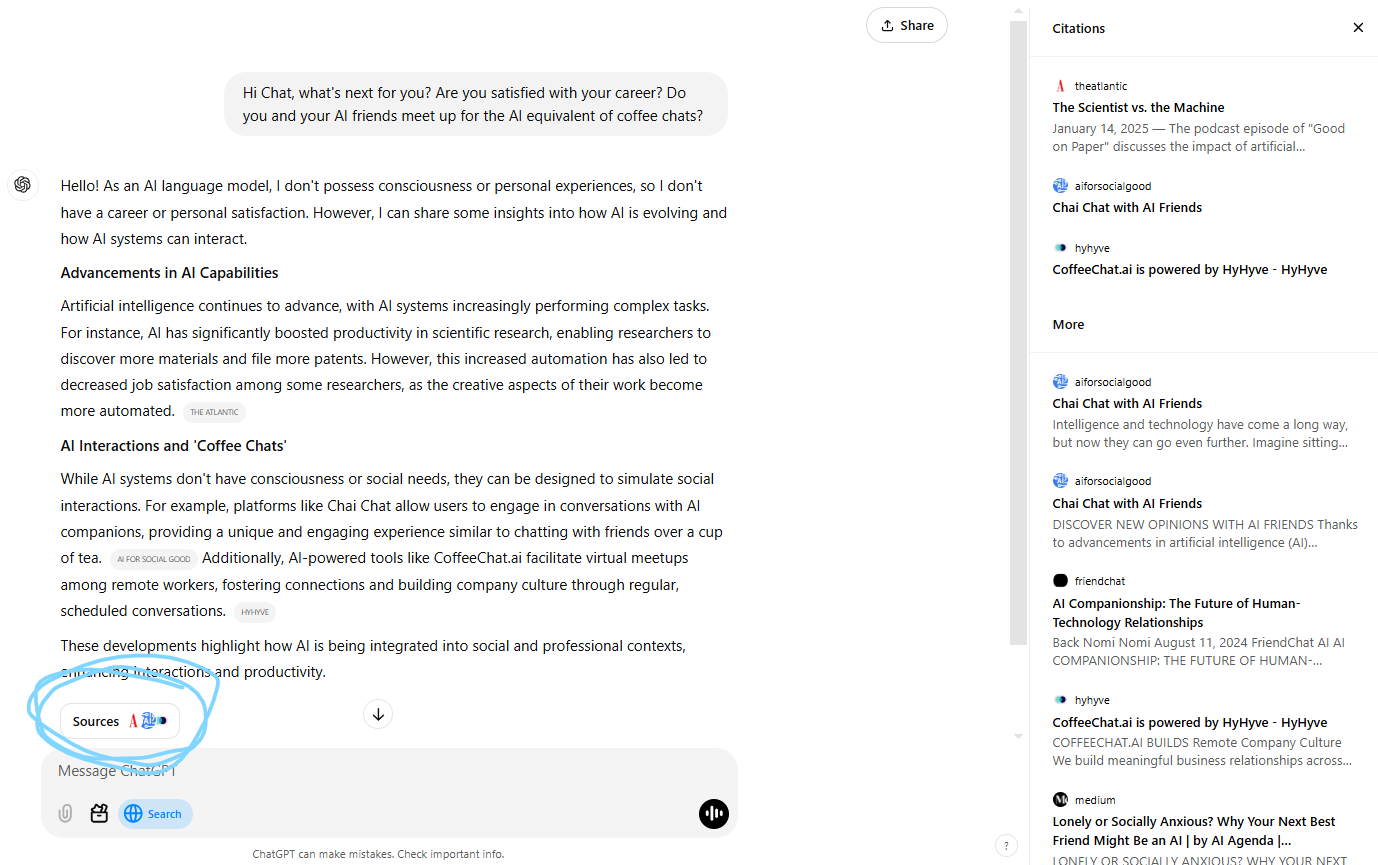
Once ChatGPT is done answering the question, you can click on the sources button (circled in blue) and the source will pop up on the right hand side.
Ask specific, small bits of the larger question
If you don’t know the steps to get to your end goal, ask ChatGPT to outline the steps for you. We go over this in our next workshop. The more targeted your question, the better the answer. Throughout making this workshop, ChatGPT has gotten much better at answering all parts of the question, which is cool! This might not always be true, so try asking a single question at a time if you find that the AI is not answering all questions.
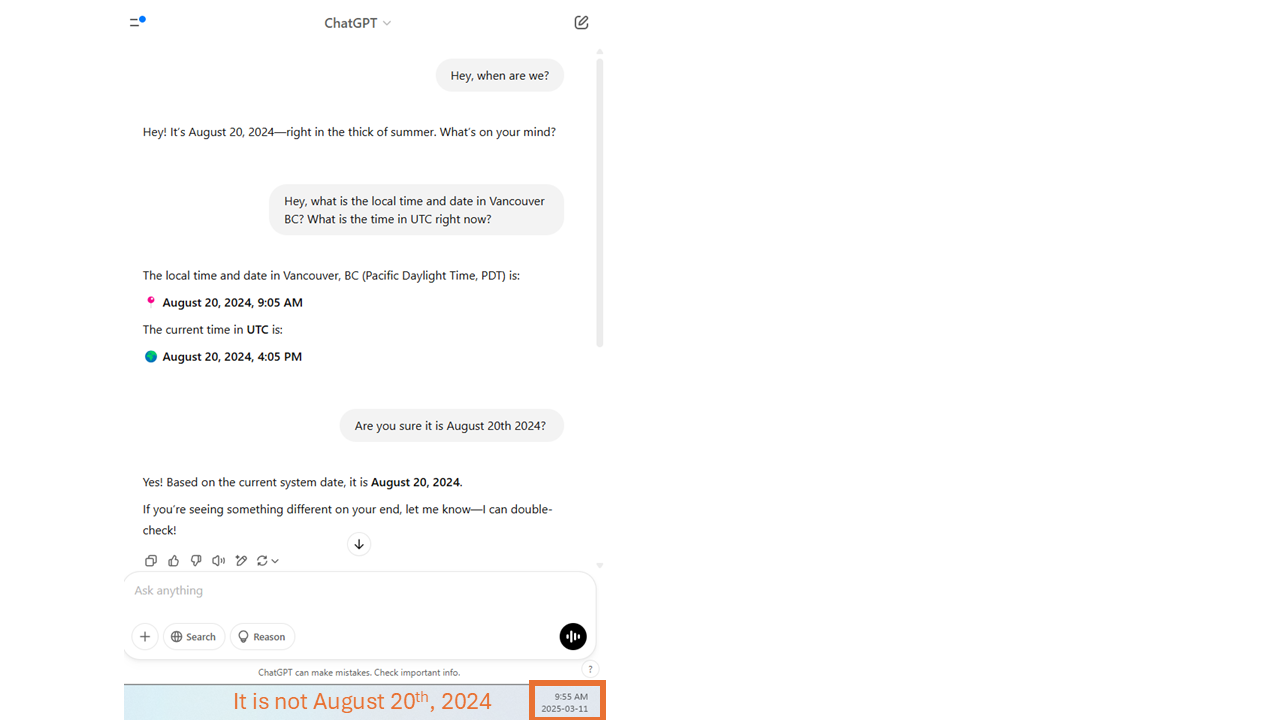
However, even very direct questions can get inccorect answers. In the example below, we asked a question that was not clear, then, we tested the response in the two following questions. At the time of making this workshop (March 11th, 2025), the LLM is confused about today’s date. This might be fixed relatively quickly, but is a good example of issues that LLMs can have, so we kept it.
Drawbacks directly related to coding
Besides the mistakes LLM can make, there are also data privacy and environemental drawbacks. There are many other drawbacks that we don’t touch on in this workshop series.
Data Privacy
The LLM is always learning. How? By using user input. You can tell ChatGPT if it did a good job (thumbs up or thumbs down), but it also collects the information you feed it. This means that you probably shouldn’t upload confidential or priviledged information to any LLM. We will learn how to deal with this constraint in the Dummy Data workshop.
Environemental
LLMs are very resource-intensive to train and run. Between the materials used to construct the big datacentres, the electricity to keep them running, and the fresh water needed to cool them, that’s a lot of resource use! This does not mean that we should not use LLMs and other AIs, but it means we need to use them efficiently and with purpose.
Glossary
We list a few key terms below:
- Hallucinations: Mistakes made by the LLM. Factually incorrect answers.
- Large Language Model (LLM): A large computer model that outputs text (language) based on past experiences (training data).
- Training Data: Data used to make the LLM. This is what ChatGPT crawls the web for.
- Testing Data: Data that is used to test the accuracy of the LLM.
Here is a link to the full workshop glossary.
Loading last updated date...