Understanding website structure
View slides for this section
Website content is usually represented using HTML, or Hypertext Markup Language. Web servers make HTML content available to browsers using a data transfer protocol called HTTP (Hypertext Transfer Protocol). Two of the most common HTTP request methods are get (to request data from a server) and post (to send data to a server).
Web scraping tools use a website’s HTML structure to navigate the page and identify the content to scrape. Effective use of web scraping tools requires a basic understanding of how web pages are structured. Sites whose underlying structure is well organized and descriptive are usually easier to scrape.
Using Browser “Inspect” tools
Most browsers have built-in “inspect” tools that allow you to explore the HTML structure of a web page. In most browsers (including Chrome, Firefox, and Edge) right-click any part of a page and select Inspect or Inspect element to open a panel showing how the selected content is represented in the HTML.
In Safari inspect element is not enabled by default.
To enable in Safari go to Preferences -> Advanced and enable Show Developer menu in menu bar.
This screenshot below shows the Inspect tool applied to a web page accessed with Chrome: http://econpy.pythonanywhere.com/ex/001.html. The page is a list of buyer names and item prices.
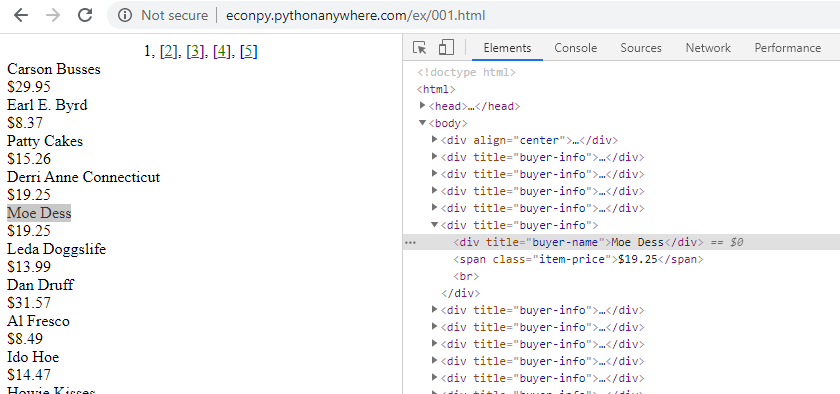
In a simple site like this it is easy to see the correlation between displayed content and HTML elements. You can expand the HTML elements in the inspection window to reveal other content and hover over elements to highlight the corresponding section in the web page.
Web scrapers navigate the HTML structure using XPath, a language that identifies and selects content nodes on the site. In the example above all buyer names are contained in <div> elements like this
<div title="buyer-name">Moe Dess</div>
The XPath expression that identifies all “buyer-name” nodes on the page is
//div[@title="buyer-name"]
Scraping examples
To help illustrate how scrapers use HTML to identify content we will use the Data Miner extension for Chrome (also available for Microsoft Edge). Links for downloading Data Miner are available from the workshop Setup page.
The Data Miner extension is an accessible way to introduce web scraping concepts. It’s a helpful learning tool but more sophisticated scraping is usually accomplished with scripts (e.g. Python, R), especially in research were reproducibility is important.
Scraping example 1: search results from Google Scholar.
1 Perform a search in Google Scholar
- Visit https://scholar.google.com/
- Enter your search terms and run a search. Stay on the search result page.
2 Use an existing “recipe” to scrape search results
We will use an existing Data Miner recipe to systematically scrape bibliographic data from the first page of Google Scholar results.
- Open the Data Miner plugin in Chrome or Edge browsers.
- Click “Scrape this page” to open the Data Miner interface.
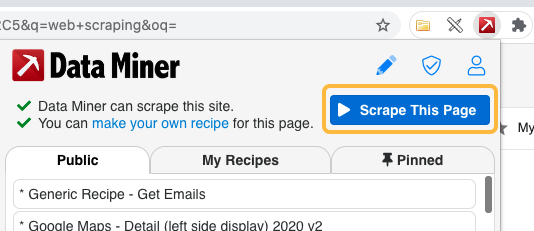
- The Data Miner page will open in a new window. In the left-hand menu click Page Scrape, then switch to the Select a Recipe tab and select a “Google Scholar” public recipe. Hover over the recipe and click Select and Scrape (see video below)
After clicking Select and Scrape, move to the Download tab to review and optionally download the scraped content.
Scraping example 2: Member of Parliament addresses.
In the previous example we used a public recipe designed for Google Scholar search results pages. In this example we will create our own recipe to selectively extract he content we want from any page.
- In the Chrome browser go to https://ourcommons.ca/members/en/addresses/
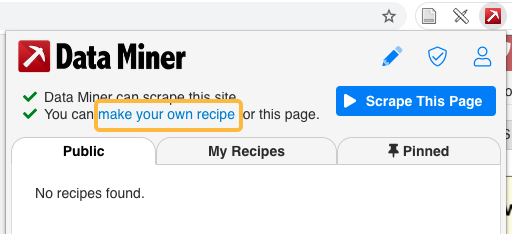
- Open the Data Miner plugin and select “make your own recipe.”
- In the Recipe Creator click through the tabs to select the Type, Rows, and Columns for your recipe.
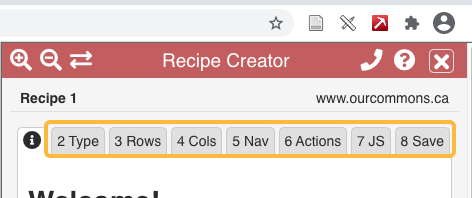
When given the option, choose the Advanced settings instead of the “Easy Row Finder” or the “Easy Column Finder.” This will help you understand the relationship between your choices and the underlying HTML structure of the page you are scraping. 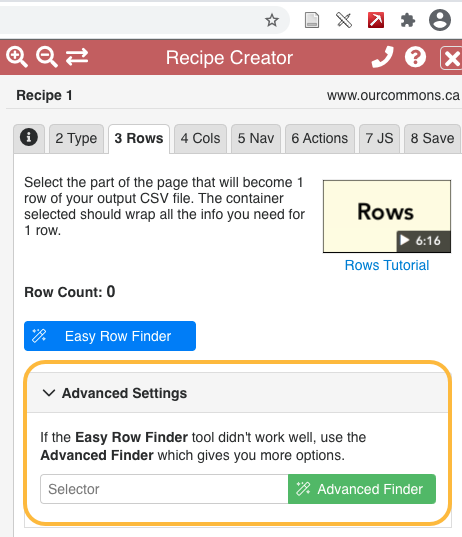
Loading last updated date...