Concepts in Large Language Models
Tokenization
- Types of Tokenization:
- Word Tokenization: Splits text into individual words. For instance, “Fine-tuning is fun” becomes
["Fine-tuning", "is", "fun"]. - Subword Tokenization: Breaks down words into smaller units to handle out-of-vocabulary (OOV) words and morphological variations. For example, “fine-tuning” might be split into
["fine", "-", "tuning"]. - Character Tokenization: Treats each character as a token, which can be useful for languages with complex word forms or to handle rare words.
- Word Tokenization: Splits text into individual words. For instance, “Fine-tuning is fun” becomes
- Unified Vocabulary:
- A model’s vocabulary is constructed from the training corpus and includes a list of all possible tokens the model might encounter. Each token is associated with a unique identifier. For example, in a vocabulary:
- “Fine-tuning” -> ID
101 - “is” -> ID
102 - “fun” -> ID
103
- “Fine-tuning” -> ID
- A model’s vocabulary is constructed from the training corpus and includes a list of all possible tokens the model might encounter. Each token is associated with a unique identifier. For example, in a vocabulary:
- Tokenization Example:
- Sentence: “Tokenization is essential.”
- Tokenized:
["Tokenization", "is", "essential", "."] - IDs:
["201", "202", "203", "204"]
- Handling OOV Tokens:
- Tokens not present in the vocabulary are managed using techniques like subword tokenization. For instance, “supercalifragilisticexpialidocious” might be broken into smaller, known subwords or characters to be processed.

_Image from: https://teetracker.medium.com/llm-fine-tuning-step-tokenizing-caebb280cfc2
In the context of large language models (LLMs), the vocabulary used for tokenization is generally fixed before the pre-training phase of the model. This fixed vocabulary is created using a process that involves analyzing a large corpus of text with techniques such as Byte-Pair Encoding (BPE), WordPiece, or SentencePiece. The vocabulary is determined based on the most efficient set of subwords or tokens and is then used consistently throughout both the pre-training and fine-tuning stages.
This vocabulary generation occurs during a setup phase, separate from the actual pre-training of the model. Once the vocabulary is established, it does not change during the model’s training. This is distinct from the model learning to predict or understand sequences of these tokens, which happens during pre-training and fine-tuning.
For example, if you have a pre-trained model like GPT-3 or BERT and want to fine-tune it on a task such as sentiment analysis or named entity recognition, you would use the same tokenizer (with its fixed vocabulary) that was used during the pre-training of the model. This ensures consistency in how the text is tokenized and processed by the model.
This process is common in fine-tuning tasks because it ensures that the model’s understanding of the tokenized text remains consistent across different phases, leading to better performance and easier integration.
Embeddings
Embeddings are numerical representations of words or tokens in a continuous vector space. They are crucial in enabling models to understand and process language. Unlike one-hot encoding, which represents words as discrete, high-dimensional vectors, embeddings capture semantic relationships1 between words in a dense, lower-dimensional space.
How Embeddings Work
- Dense Vectors: Each word is represented by a dense vector of fixed size, where each dimension captures a different aspect of the word’s meaning.
-
Semantic Similarity: Words with similar meanings are represented by vectors that are close to each other in the embedding space.
-
Example: Let’s consider the sentence “The cat sat on the mat.”
- Original Words: [“The”, “cat”, “sat”, “on”, “the”, “mat”]
- Embedding Representation:
- “The”:
[0.1, -0.2, 0.3, ...] - “cat”:
[0.2, 0.1, -0.3, ...] - “sat”:
[0.0, -0.1, 0.2, ...] - “on”:
[0.1, -0.3, 0.2, ...] - “mat”:
[0.3, -0.2, -0.1, ...]
- “The”:
In this example, each word is mapped to a vector in a high-dimensional space (e.g., 100-dimensional). The vectors capture semantic relationships: words like “cat” and “mat” might be closer to each other in the vector space compared to “cat” and “sat,” reflecting their related meanings in context.
- Learning Embeddings:
- Training Process: Embeddings are learned during the training of models such as Word2Vec, GloVe, or BERT. The model adjusts the vectors based on context and co-occurrence patterns in the training data.
- Contextual Information: Modern models like BERT produce contextual embeddings, where the representation of a word changes based on its surrounding words. For example, the word “bank” will have different embeddings in “river bank” versus “financial bank.”
Positional Encoding
Positional Encoding is a technique used in transformer models to provide information about the position of tokens in a sequence. Unlike recurrent neural networks (RNNs) or convolutional neural networks (CNNs), transformers do not have inherent mechanisms to understand token order. Positional encoding helps address this by encoding the position of each token in a way that the model can incorporate into its processing. Positional encoding injects order information into the input embeddings to ensure that the model understands the sequence of tokens. This is crucial because the transformer architecture processes all tokens simultaneously and lacks the sequential processing of RNNs.
Example:
- Token Sequence: Consider a sentence “The cat sat.”
- Positions: Each token is assigned a positional encoding vector:
- “The”: Positional encoding vector for position 1
- “cat”: Positional encoding vector for position 2
- “sat”: Positional encoding vector for position 3
- Combined Representation: The final representation for each token is the sum of its word embedding and its positional encoding, allowing the model to use both the word’s meaning and its position in the sentence.
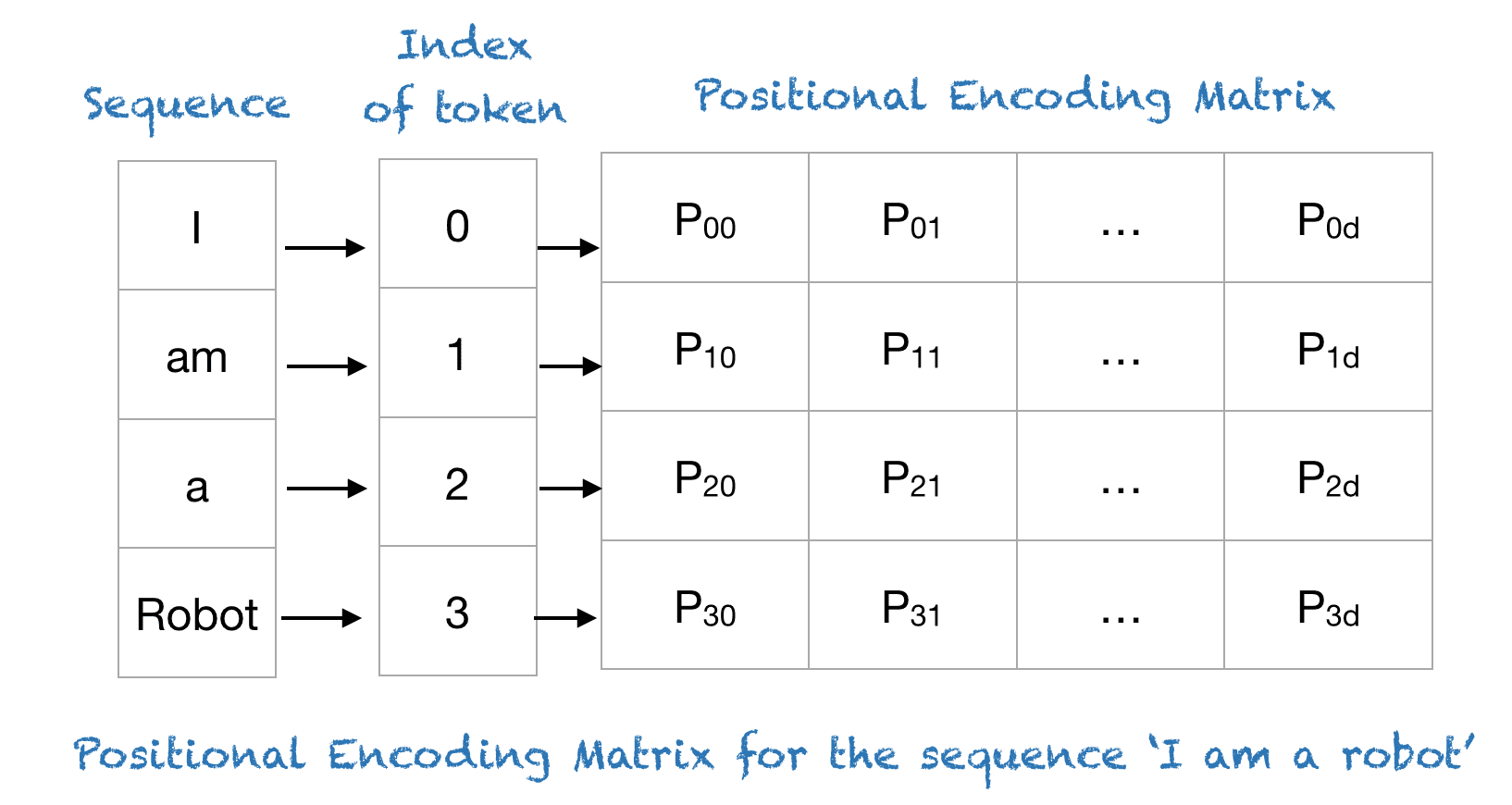 Image from: https://machinelearningmastery.com/a-gentle-introduction-to-positional-encoding-in-transformer-models-part-1/
Image from: https://machinelearningmastery.com/a-gentle-introduction-to-positional-encoding-in-transformer-models-part-1/
Quantization
Quantization is a technique used to reduce the computational and memory footprint of machine learning models, including large language models (LLMs). It involves mapping continuous values (like those in model weights) to a smaller set of discrete values. This process can significantly improve the efficiency of deploying models without a substantial loss in performance.
Types of Quantization
- Post-Training Quantization:
- Applied after the model has been trained.
- Reduces precision of weights and activations (e.g., from 32-bit floating point to 8-bit integers).
- Quantization-Aware Training (QAT):
- Involves training the model with quantization in mind.
- Helps the model adjust to the lower precision during training, leading to better performance after quantization.
Benefits
- Reduced Model Size: Smaller model size means less storage requirement.
- Faster Inference: Lower precision computations are faster and require less power.
- Lower Memory Usage: Decreased memory footprint allows deployment on resource-constrained devices.
Example
- Original Weights: 32-bit floating point values.
- Quantized Weights: 8-bit integer values.

Image from: https://www.tensorops.ai/post/what-are-quantized-llms
LoRa (Low-Rank Adaptation)
LoRa (Low-Rank Adaptation) is a technique for fine-tuning large pre-trained models efficiently. It focuses on adapting a small number of parameters while keeping most of the original model parameters unchanged. This method allows for effective customization of pre-trained models with less computational cost.
How LoRa Works
- Low-Rank Decomposition:
- Decomposes weight matrices into low-rank components.
- Only the low-rank components are updated during fine-tuning. This helps to reduce the number of parameters that need to be optimized, making the process more efficient.
- Parameter Efficiency:
- Reduced Computational Overhead: By updating only the low-rank components, the number of parameters to be trained is significantly reduced. This results in less computational power and memory usage compared to traditional fine-tuning methods.
- Effective Adaptation: The low-rank components capture the essential variations needed for the specific task or domain, allowing the model to adapt effectively without a full retraining of all parameters.
- Implementation:
- Initialization: Begin with a pre-trained model and decompose its weight matrices into low-rank approximations.
- Fine-Tuning: Train the low-rank components on the new dataset while keeping the original model weights frozen. This involves updating only the low-rank matrices.
- Integration: After fine-tuning, the updated low-rank components are integrated back into the model to make predictions on new data.
QLoRa (Quantized Low-Rank Adaptation)
QLoRa is an extension of LoRa that combines the benefits of quantization with low-rank adaptation. It focuses on reducing the memory footprint and computational cost even further by quantizing the low-rank components.
- Quantized Low-Rank Components:
- Quantizes the low-rank components to lower precision (e.g., 8-bit integers).
- This reduces the storage and computational requirements of the fine-tuning process.
- Why Use QLoRa:
- Increased Efficiency: Combining quantization with LoRa allows for even greater reductions in model size and computation compared to using LoRa alone.
- Memory Constraints: Ideal for scenarios where hardware resources are limited, such as deployment on edge devices or mobile platforms.
- Faster Inference: Lower precision arithmetic operations speed up inference and reduce power consumption.
- Implementation of QLoRa:
- Quantization: Apply quantization to the low-rank components after decomposing the weight matrices.
- Fine-Tuning: Update the quantized low-rank components during fine-tuning.
- Deployment: Use the quantized model for inference, benefiting from reduced resource usage.
Benefits
- Efficiency: Reduces time and computational resources needed for fine-tuning and inference.
- Scalability: Makes it feasible to adapt large pre-trained models for specific tasks with limited hardware resources.
- Flexibility: Allows for quick adjustments to pre-trained models for different tasks or domains without extensive retraining.
- Reduced Memory Usage: Quantization further decreases memory footprint, making the model suitable for resource-constrained environments.
Example
Imagine you have a large language model pre-trained on a general corpus and you want to fine-tune it for sentiment analysis on a specific dataset. Using LoRa, you decompose the model’s weight matrices into low-rank components and update these components with your sentiment analysis data. If you use QLoRa, you would quantize these low-rank components to save even more resources and accelerate inference.
References
Complete Guide to Subword Tokenization Methods in the Neural Era Summary of the tokenizers Word Embedding: Basics Parameter-Efficient Fine-Tuning of Large Language Models with LoRA and QLoRA
- Semantic relationships refer to the connections between words based on their meanings. In the context of embeddings, this means that words with similar meanings or usage contexts are represented by vectors that are closer together in the vector space. For example, words like "king" and "queen" might be close to each other because they share similar semantic properties. This proximity helps models understand and process language more effectively.↩
Loading last updated date...