Understanding Large Language Models (LLMs)
What are LLMs?
Large Language Models (LLMs) are sophisticated machine learning models designed to process, understand, and generate human-like text. These models are powered by vast amounts of textual data and utilize advanced algorithms to perform a range of language-related tasks. Key applications include:
- Translation: Converting text from one language to another while preserving meaning and context.
- Summarization: Condensing lengthy documents into concise summaries without losing essential information.
- Question-Answering: Providing accurate responses to user queries based on the context of the question and the model’s training data.
- Text Generation: Creating coherent and contextually relevant text for various purposes, such as writing assistance or creative content.
How Do LLMs Work?
LLMs are typically built on neural network architectures called transformers. Here’s a general overview of the architecture:
General LLM Architecture
- Embedding Layer:
- Tokenization: The first step involves breaking down text into smaller units called tokens. These tokens can be words, characters, or subwords.
- Embedding: Tokens are converted into numerical vectors (embeddings) that represent their meanings. This transformation allows the model to process and understand the tokens in a mathematical form.
- Positional Encoding:
- Encoding Token Position: Since transformers do not inherently understand the order of tokens, positional encodings are added to embeddings. These encodings provide information about the position of each token in the sequence, enabling the model to consider the order when processing the text. Each token’s final representation is a combination of its word embedding and positional encoding, allowing the model to consider both the token’s meaning and its location in the sentence.
- Transformer Blocks:
- Self-Attention Mechanism: Each token in the input text is compared with every other token to determine its relevance. This mechanism helps the model to weigh the importance of different words in the context of each other, capturing relationships and dependencies across the entire sequence.
- Multi-Head Attention: Multiple attention mechanisms (heads) are used in parallel to capture different aspects of the token relationships. This allows the model to focus on various parts of the text simultaneously, providing a richer representation.
- Feed-Forward Neural Networks: After the attention mechanism, the data is passed through feed-forward neural networks. These networks apply transformations to further process and refine the token representations.
- Layer Normalization and Residual Connections: To improve training stability and efficiency, normalization techniques are applied, and residual connections are used to help gradients flow through the network.
- Output Layer:
- Text Generation: The processed token representations are used to generate output text. In the case of generative models like GPT, this involves predicting the next word or sequence of words based on the input context.
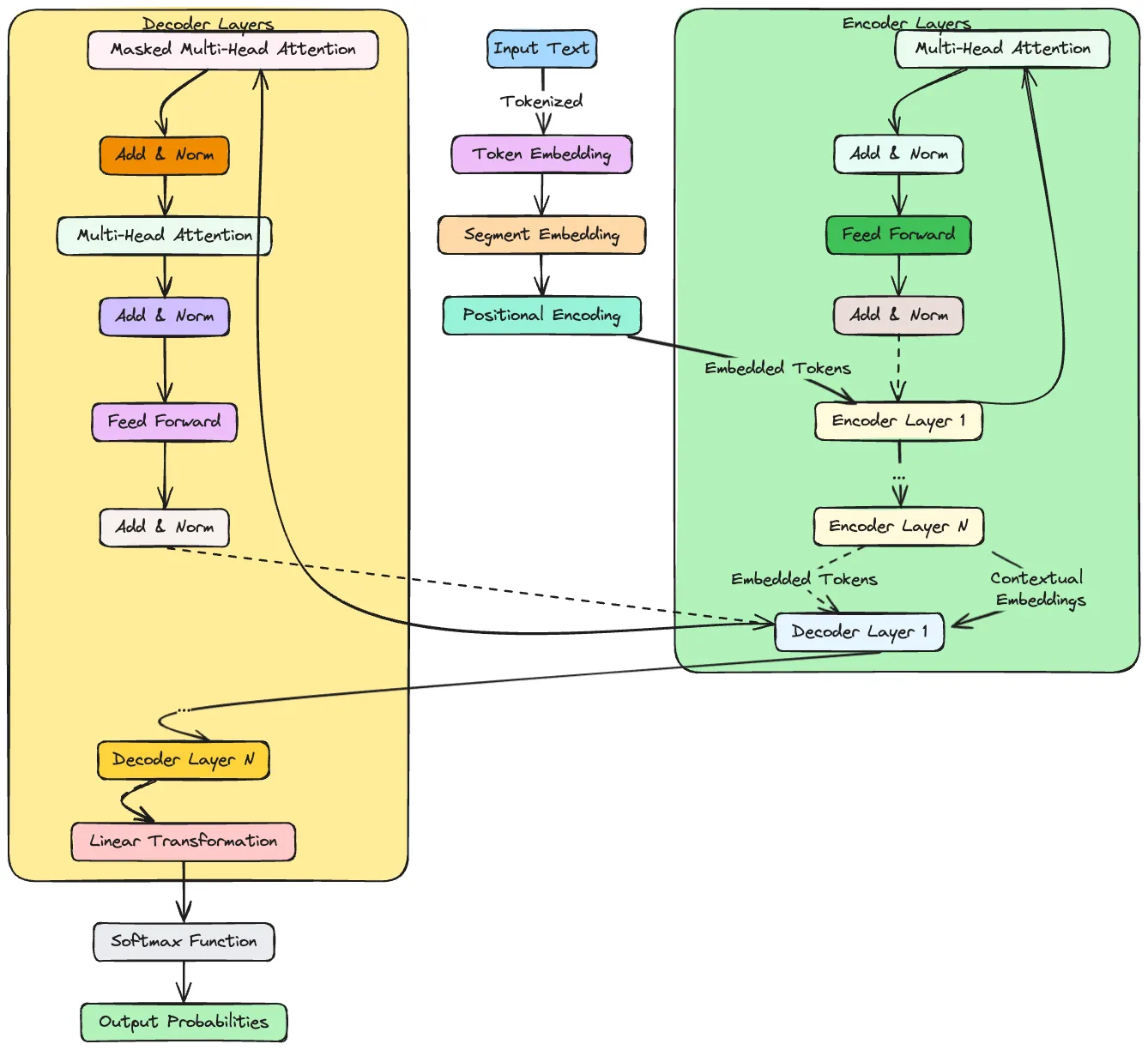
Image from: https://scientyficworld.org/how-do-large-language-models-work/0
Training and Fine-Tuning
Training LLMs involves several crucial steps to ensure the model learns effectively and performs well on various tasks. This section explores the general training process and various fine-tuning techniques.
1. Data Collection
- Diverse Datasets: LLMs are trained on extensive and varied Corpora1 that include text from books, articles, websites, and other sources. The diversity of the data helps the model learn a broad range of language patterns and knowledge.
2. Pre-Training
- Objective: The primary goal of pre-training is to enable the model to grasp general language patterns, grammar, and facts. This involves predicting the next token in a sequence (e.g., predicting the next word in a sentence) using a large-scale dataset.
- Self-Supervised Learning: Pre-training is often achieved using self-supervised learning techniques, where the model generates its own training labels from the data, such as predicting missing words or sentences.
3. Fine-Tuning
After pre-training, the model undergoes Fine-Tuning to adapt it to specific tasks or domains. Fine-tuning involves further training the model on a specialized dataset to improve its performance on particular applications. For example, consider a pre-trained language model like GPT-3. Without fine-tuning, the model can generate coherent text but might not excel in domain-specific tasks. For instance, if the goal is to generate legal documents, the general training may not suffice. Fine-tuning the model on a dataset of legal texts helps it learn the relevant jargon and specifics, thereby improving its ability to produce accurate and contextually appropriate content.
4. Evaluation
- Metrics: Model performance is assessed using various metrics depending on the task. Common metrics include accuracy, F1 score, BLEU score (for translation), and perplexity (for language modeling).
- Validation and Testing: The model’s generalization capabilities are tested on separate validation and test datasets that were not used during training to ensure it performs well on unseen data.

Image from: https://www.supa.so/post/how-large-language-models-llms-learn
Fine-Tuning Methods
Various Fine-Tuning methods can be employed, including:
1. Supervised Fine-Tuning (SFT)
- Dataset: Uses a labeled dataset where each input has a known correct output or label. This dataset is used to refine the model’s performance on specific tasks.
- Process: The model’s parameters are adjusted based on labeled examples to minimize the error between predictions and actual labels using supervised learning techniques such as classification or regression.
- Use Cases: Effective for tasks requiring domain-specific knowledge or detailed understanding, such as sentiment analysis or named entity recognition.
- Challenges: Requires high-quality labeled data, can suffer from overfitting if not managed carefully, and needs significant computational resources.
2. Unsupervised Fine-Tuning
- Self-Supervised Learning: The model generates its own labels from the data, such as predicting masked words or sentences. Examples include masked language modeling.
- Contrastive Learning: The model learns by comparing similar and dissimilar pairs of data, bringing similar examples closer in the representation space while pushing dissimilar ones apart.
- Use Cases: Useful for learning from unlabeled data and improving representations or embeddings.
3. Reinforcement Learning Fine-Tuning
- Reward-Based Training: The model is trained based on rewards received for correct or desirable outputs. This feedback helps the model improve its decision-making over time.
- Policy Gradient Methods: Adjusts the model parameters based on the gradient of the expected reward to maximize cumulative reward.
- Use Cases: Effective in scenarios like conversational agents where the model’s responses are guided by user feedback or engagement metrics.
4. Domain-Adaptive Fine-Tuning
- Domain Adaptation: Fine-tunes the model on data from specific domains (e.g., medical, legal) to enhance performance in those areas while retaining general language understanding.
- Continual Learning: Involves updating the model incrementally with new data from specific domains to keep it relevant without forgetting previously learned knowledge.
- Use Cases: Tailors the model to specific industry or field requirements.
5. Multi-Task Fine-Tuning
- Shared Representations: Trains the model on multiple tasks simultaneously, allowing it to learn common features and improve performance across tasks.
- Task-Specific Heads: Employs different output layers (heads) for each task, enabling the model to specialize in each task while sharing underlying knowledge.
- Use Cases: Improves performance on tasks like text classification, sentiment analysis, and translation by leveraging shared knowledge.
Challenges and Potential Issues
- Overfitting: Occurs when the model performs well on training data but poorly on new, unseen data. This can happen if the model becomes too specialized to the training data.
- Mitigation: Techniques such as regularization, dropout, and careful monitoring on validation data help prevent overfitting.
- Bias and Fairness: LLMs can inherit biases present in the training data, leading to biased or unfair outputs.
- Mitigation: Involves careful data curation, implementing bias mitigation techniques, and regularly evaluating model fairness.
- Error Sources: Poor data quality, insufficient diversity in training data, and limitations in the model’s architecture can lead to inaccurate or misleading outputs.
References
- How do Large Language Models work?
- What are Large Language Models(LLMs)?
- Fine-Tuning a pre-trained LLM with unlabelled dataset
- LLM domain adaptation using continued pre-training — Part 1/4
- ReFT: Enhancing LLMs with reinforced fine-tuning
- Single Vs Multi-Task LLM Instruction Fine-Tuning
- Corpora (singular: "corpus") refers to large and structured sets of textual data. In the context of LLMs, corpora are collections of written or spoken texts that serve as the training data, helping the model to learn language patterns, syntax, semantics, and other linguistic elements. These datasets can include diverse sources such as books, research papers, websites, social media posts, and more, contributing to the richness and generalizability of the model's knowledge. ↩
Loading last updated date...