A Sample Python Program
We might skip this program depending on group needs
Fetching data from the UN and assessing the most discussed topics
Assume you have a function that is a black-box. You don’t need to understand it, just use it to get data from a web page. The function get_text_from takes a resource r and return the text from that resource as a list.
Input
import requests
from bs4 import BeautifulSoup
# https://stackoverflow.com/questions/328356/extracting-text-from-html-file-using-python
def get_text_from(r):
page = requests.get(r)
soup = BeautifulSoup(page.text)
for script in soup(["script", "style", "pre"]):
script.extract()
text = soup.get_text()
lines = (line.strip() for line in text.splitlines())
chunks = (phrase.strip() for line in lines for phrase in line.split(" "))
txt = '\n'.join(chunk for chunk in chunks if chunk)
return txt.split('\n')
- For more details, we encourage you to register into the Introduction to Web Scraping Workshop
Input
def discusses_topic(speech, topic):
cnt = 0
for line in speech:
words_in_sentence = line.split(' ')
if any(word in topic for word in words_in_sentence):
cnt += 1
return cnt
We want to define some topics, e.g., climate change, economy, peace, etc. We will use the discusses_topic to create a dictionary with the topic and how often it appears in UN discussions (see references for list of statements).
Input
un_statements = [
"https://www.un.org/sg/en/content/sg/speeches/2020-03-10/wmo-state-of-the-climate-2019-report-remarks",
"https://www.un.org/sg/en/content/sg/speeches/2020-02-21/2020-session-of-special-committee-decolonization-remarks",
"https://www.un.org/sg/en/content/sg/speeches/2020-02-16/remarks-sustainable-development-and-climate-change",
"https://www.un.org/sg/en/content/sg/speeches/2020-02-08/remarks-the-blue-economy-event",
"https://www.un.org/sg/en/content/sg/speeches/2020-03-31/remarks-launch-of-report-the-socio-economic-impacts-of-covid-19",
"https://www.un.org/sg/en/content/sg/speeches/2020-03-26/remarks-g-20-virtual-summit-covid-19-pandemic",
"https://www.un.org/sg/en/content/sg/speeches/2018-06-19/remarks-press-encounter-pm-solberg-norway",
"https://www.un.org/sg/en/content/sg/speeches/2018-06-09/secretary-general-comments-44th-g7-summit",
"https://www.un.org/sg/en/content/sg/speeches/2020-02-04/remarks-journalists-priorities-for-2020-and-work-of-organization",
"https://www.un.org/sg/en/content/sg/speeches/2019-11-11/remarks-the-paris-peace-forum"
]
peace = ["peace", "war", "cease", "together", "heal", "truce", "reconciliation", "union", "treaty"]
environment = ["global", "environment", "climate", "change", "natural", "warming", "temperature", "resources"]
economy = ["economy", "business", "development", "employment", "progress", "job", "capital", "dollars"]
Input
cnt_peace = 0
cnt_environment = 0
cnt_economy = 0
for resource in un_statements:
txt = get_text_from(resource)
cnt_peace += discusses_topic(txt, peace)
cnt_environment += discusses_topic(txt, environment)
cnt_economy += discusses_topic(txt, economy)
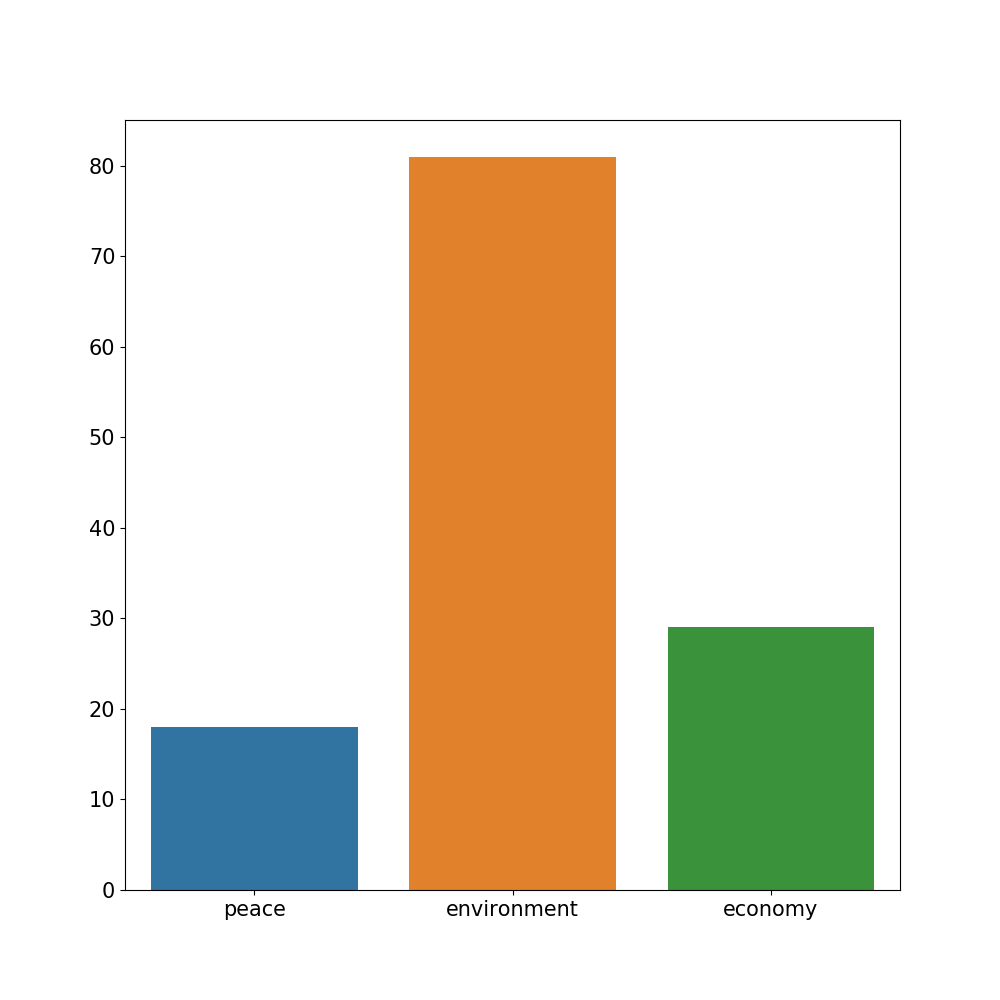
data = dict(
topic=["peace", "environment", "economy"],
count=[cnt_peace, cnt_environment, cnt_economy]
)
Input
sns.barplot(x='topic', y='count', data=data)
Output will be similar to: