Another Sample Python Program
We might skip this program depending on group needs
Which Canada city is the coldest?
Assume you have data about the average of Canada’s largest cities, i.e., Vancouver, Toronto, Montreal and Ontario. Can we statistically test whether there is difference in the average temperatures between each city?
Input
import pandas as pd
import numpy as np
from datetime import datetime
from scipy import stats
def remove_nan(lst):
return [x for x in lst if str(x) != 'nan']
We need to do some pre-processing:
- Assure we select only cities in Canada
- Create a nee column extracting the year from a date
Input
mydata = pd.read_csv("canada.csv", error_bad_lines=False)
mydata = mydata[mydata["Country"] == "Canada"]
mydata['year'] = mydata.apply(lambda row: datetime.strptime(row['dt'], '%Y-%m-%d').year, axis = 1)
Then we create three variables each containing the average temperature of a city
Input
Vancouver = mydata[mydata["City"] == "Vancouver"]["AverageTemperature"].tolist()
Toronto = mydata[mydata["City"] == "Toronto"]["AverageTemperature"].tolist()
Ontario = mydata[mydata["City"] == "Ontario"]["AverageTemperature"].tolist()
As some cells in the original data are empty, our list might contain nan. Let’s remove them
Input
Vancouver = remove_nan(Vancouver)
Toronto = remove_nan(Toronto)
Ontario = remove_nan(Ontario)
It’s time to compare!
Vancouver vs Toronto
Input
print("Vancouver mean temperature", np.mean(Vancouver))
print("Toronto mean temperature", np.mean(Toronto))
print(stats.ttest_ind(Vancouver, Toronto))
Output:
Vancouver mean temperature 8.512162465627865
Toronto mean temperature 5.7739111747851
Ttest_indResult(statistic=15.243424692356555, pvalue=1.0774285600646815e-51)
Toronto vs Ontario
Input
print("Ontario mean temperature", np.mean(Ontario))
print("Toronto mean temperature", np.mean(Toronto))
print(stats.ttest_ind(Ontario, Toronto))
Output:
Ontario mean temperature 17.055758725341427
Toronto mean temperature 5.7739111747851
Ttest_indResult(statistic=43.16346037718508, pvalue=0.0)
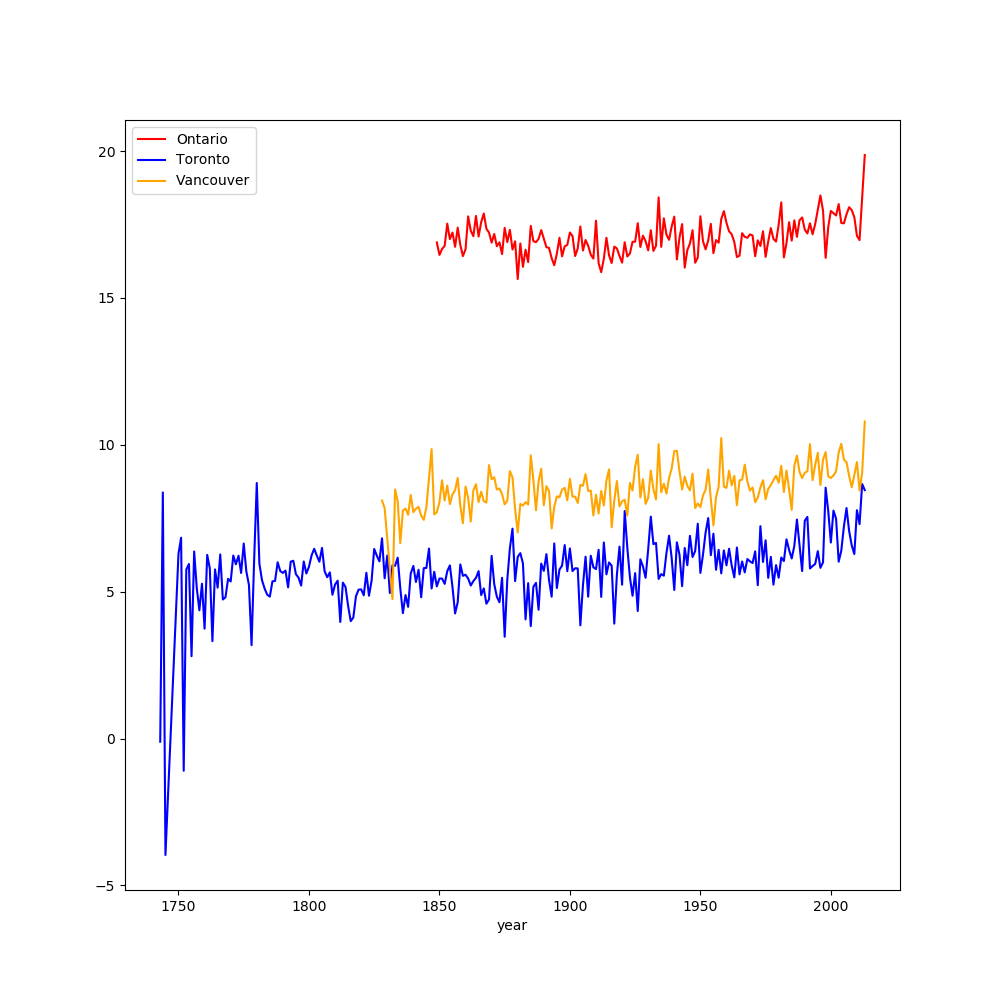
Visual Comparison
Input
df = mydata.groupby(['year', 'City', 'color']).agg({'AverageTemperature' : 'mean'})
df = df.reset_index()
grouped = df.groupby('City')
fig, ax = plt.subplots(1)
idx = 0
colours = ["red", "blue", "orange"]
for key, group in grouped:
group.plot(ax=ax, x="year", y="AverageTemperature", label=key, color=colours[idx])
idx += 1
Output will be similar to: