Table of contents
Is your data FAIR?
The FAIR Data Principles (Findable, Accessible, Interoperable, and Reusable), published in Scientific Data in 2016, are a set of guiding principles proposed by a consortium of scientists and organizations to support the reusability of digital assets. These principles have since been adopted by research institutions worldwide. The guidelines are timely as we see the unprecedented volume, complexity, and speed in the creation of data.
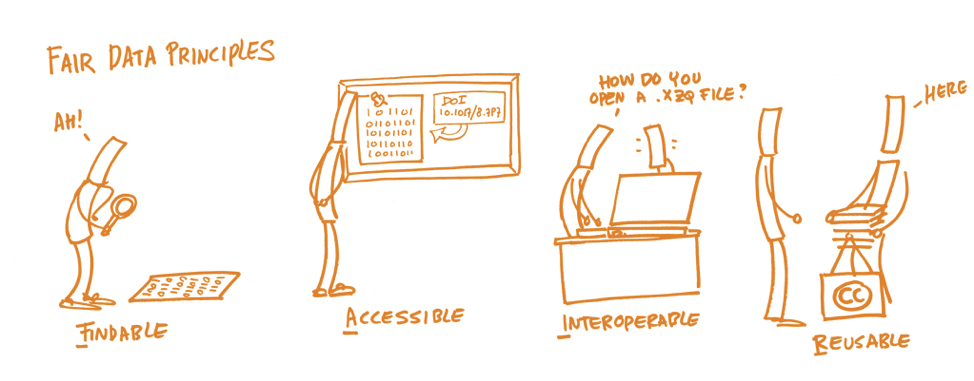
Image: OpenAIRE.
Findable
Findable data is discoverable thanks to its metadata.
Accessible
Accessible data is always available and obtainable, this does not mean the files are open,
rather that you can access the metadata regarding the files.
Interoperable
Interoperable data is able to be used by many researchers from many locations.
Reusable
Reusable data is described, licensed, and shared in such a way that wide reuse is possible.
All data can be FAIR, but not all FAIR data is open. OpenAIRE states that data should be “as open as possible, as closed as necessary.” Not all data can be fully open, but it should still be findable at the metadata level.
Want to make your data more FAIR? Metadata, the descriptive data about your project, supports your project’s ability to be FAIR!
Metadata
Metadata is often described as “data about data” and helps answer the questions of who, what, when, where, why. This descriptive data is essential for creating FAIR and open data, and ensuring that the datasets you preserve will be accessible for many years to come.
![]() Metadata makes it easier for researchers to:
Metadata makes it easier for researchers to:
- share their data,
- publicize their data,
- locate and retrieve data sets from others.

Three of the most common categories
- Descriptive: Descriptive metadata describes the content and context of your data at both the dataset and item level.
- Examples: title, author, keywords
- Administrative: Administrative metadata includes information needed to use the data.
- Examples: software requirements, copyright, licensing
- Structural: Structural metadata describes how different datasets relate to one another, or any processing or formatting steps that were undertaken.
- Examples: Information about the relationship between datasets in a database, file formats
Reflection
Take a moment to think about your research project. What kind of descriptive, administrative
and structural metadata might you want to record?
Ensure your data is understandable
Create a README File

To ensure that fellow researchers can understand and reuse your data, it is crucial to describe what method you will use to facilitate comprehension. One effective approach is to create a robust README file. This file should include comprehensive information about your dataset (i.e. metadata), such as its contents, provenance, licensing, and instructions on how to interact with it.
You can refer to our Create a README File workshop to learn how to create a solid README file.
Data Dictionary or Codebook
In addition to the README file, you should explain how you will define all your variables in a data dictionary or codebook. This serves as a reference document that outlines the definitions and characteristics of each variable in your dataset. By clearly defining and documenting your variables, you enable other researchers to understand the structure and meaning of your data, promoting its effective reuse and interpretation.
Alternatively, you can utilize your README file to provide this information.

Congrats!
You have finished the documentation section! Please also make sure you record metadata during the research process while the data is still active and store it alongside your research data.

Need help?
Please reach out to research.data@ubc.ca for assistance with any of your research data questions.
Loading last updated date...