Introduction to Data De-Identification
Although it is good practice to share our research data and findings, we need to consider precautions when conducting ethical, reliable, and responsible research. Sensitive data requires careful handling and security to protect participant privacy and confidentiality and to comply with ethical and legal requirements. Leaked sensitive data poses major harm and risks, such as revealing identities, which negatively affect the interests of people, communities, and/or animals involved in the research.
Terminology
UBC does not define the term “sensitive data”. Instead, UBC electronic information is classified using a schema outlined in UBC Information Security Standard U1 (ISS-U1). For the purposes of this workshop, however, we will use the term “sensitive data” to align with the terminology in Sensitive Data: Practical and Theoretical Considerations (Rod & Thompson, 2023, pp. 251-273).In this context, the term “sensitive data” will be treated as equivalent to information classified as “high risk” and “very-high risk” in UBC ISS-U1.
Looking for a cheat sheet? Check out our two-pager
Table of contents
What is sensitive data?
In addition to UBC’s terminology to define sensitive data, this kind of information can also be understood as “information that must be safeguarded against unwarranted access or disclosure” (Rod & Thompson, 2023, p. 252) and may relate to both humans and animals.
Examples of data that are considered “sensitive”:
- Personal health information
- Some kinds of geographical information, like the locations of endangered species
- Data protected by institutional policy
Why do we de-identify data?
Data is de-identified to minimize the risk of harm to individuals, communities, and animal species in the event of a confidentiality breach.
Data de-identification is also done to prevent possible re-identification, where participants could be isolated in a dataset and then matched to other information that could identify them with reasonable effort. The level of harm that may impact participants depends on the population, topic, and context of the data.
Examples of who may be harmed:
- Vulnerable populations
- Racialized communities
- Indigenous communities
- Politically oppressed communities
- Lower-income groups
- Children and teens
- Participants with experiences of socially sensitive topics (of a Western lens)
- Drugs (including cigarettes) and alcohol use
- Details of sexual activity and/or STD status
- Private family issues
- Relationship/domestic violence
- Loss or death in the family
- Victimization status
- Criminal/delinquent behaviour
- Health-related questions, medical conditions, and mental health questions

What makes data “sensitive”?
Within a dataset, there are different kinds of identifying pieces of information that may be included in a dataset: direct identifiers, indirect identifiers, non-identifiers, and hidden identifiers. Depending on the type, these kinds of identifiers can immediately identify a participant or can identify them when combined with other identifiers.
Direct identifiers
Direct identifiers are pieces of information that will immediately re-identify a participant. This type of information must be removed from any published dataset. Also, consider removing direct identifiers when sharing data within the research group.
Here are 15 direct identifiers compiled by Rod & Thompson (2023):
- Full or partial names or initials
- Dates linked to individuals, such as birth, graduation, or hospitalization (year alone or month alone may be acceptable)
- Full or partial addresses (large units of geography, such as a city, fall under indirect identifiers and need to be reviewed)
- Full or partial postal codes (the first three digits may be acceptable)
- Telephone or fax numbers
- Email addresses
- Web or social media identifiers or usernames
- Web or internet protocol numbers, precise browser and operating system information (these may be collected by some types of survey software or web forms)
- Vehicle identifiers, such as license plates
- Identifiers linked to medical or other devices
- Any other identifying numbers directly or indirectly linked to individuals, such as social insurance numbers, student numbers or pet ID numbers
- Photographs or individuals or their houses or locations, or video recordings containing these; medical images or scans
- Audio recordings of individuals
- Biometric data
- Any unique and recognizable characteristics of individuals (for example, a Canadian Research Chair in Physics)
Indirect identifiers (“quasi-identifiers”)
Indirect identifiers, or “quasi-identifiers”, are pieces of information that, when combined, could identify a participant. The removal of this kind of information should be evaluated in the context of what is known or may be reasonably inferred.
For example, these are likely to pose a high risk:
- Variables containing groups with small numbers of respondents
- Extreme values or unusual combinations of variables
Consider the size of the potentially-identifiable group(s) in the general population and the contextual information that accompanies the data.
Here are some examples of indirect identifiers:
- Participant surveys or interviews (who consented to have their information used for research purposes)
- Medical records
- Disability
- Tax-filer records
- Social media
- Age (can be a direct identifier for the very elderly)
- Gender identity
- Income
- Occupation or industry
- Geographic variables
- Ethnic and immigration variables
- Membership in organizations or use of specific services
Non-identifiers
Non-identifiers are pieces of information that are unlikely to identify a participant. For example:
- Ratings on a Likert scale, rankings, and opinions
- Temporary measures, like a resting heart rate or the number of times you ate a meal in the last week
However, still consider the level of sensitivity of the data. A dataset with medical information about health behaviours should be handled more carefully than a dataset with potato chip flavour ratings. Similarly, for free text responses, comments, and transcribed interviews, which also need to be considered on a case-by-case basis.
Hidden identifiers
Like indirect identifiers, hidden identifiers are pieces of non-identifying information that, when contextually combined in some way, may re-identify participants.

Exercise 1
You are a researcher investigating what factors are linked to production efficiencies – quantities and costs – of apple growers in the Pacific Northwest.
Please answer these questions based on the data collected (see below) from surveying apple growers:
- What data points are direct identifiers?
- What data points are indirect identifiers?
Exercise Dataset
Here is the collected data from surveying apple growers as a downloadable XLSX file with multiple sheets. The first sheet contains the unprocessed data, the second sheet has the answers for the direct identifiers, the third sheet has the answers for the indirect identifiers, and the fourth sheet serves as a data dictionary.
- Please note that this dataset was created for this workshop and doesn’t reflect a real study with real participants.
Consent language
Anytime human participants are involved in research, informed consent is needed. Informed consent needs to include how the collected data will be handled during the active research phase and in the future.
Try to keep in mind that many journals are now asking for a subset of data to be available, and if the original consent does not address the future availability of data, then a paper would be stuck. It is much harder to change the consent forms after the fact.
In Canada, ethical guidelines for human research participants are outlined in the Tri-Council Policy Statement (TCPS 2). To comply with these guidelines, there is specific information that needs to be included, depending on the area of research being conducted.
- The Sensitive Data Toolkit for Researchers by the Alliance contains language that can be included in the consent form to notify the participant about what happens to their data, explain the de-identification process, and more.
- The UBC ARC Information Privacy page contains considerations when working with human participant information, including consent.
Research ethics boards (REBs) of institutions are very careful about consent language to make sure privacy and confidentiality are protected, and that participants know about the extent of their participation.
Generally, consent forms should include information like:
- Research participation is voluntary
- Participation can be withdrawn from the research at any time (including the process for consent withdrawal)
- In plain and concise language, a description of the study with any potential risks and benefits to the participants. This is especially important for studies that include participants of vulnerable populations, socially taboo topics, coercion, and/or deception
- What will happen to the data: whether it will be made available to other researchers or to the public, and under what conditions, in which specific repository, in what format, and what information is included
Future use of data
When writing an application to a REB specific to the area of study, there are many things to consider. One important consideration is “what happens to the sensitive data in the future?”, which refers to how the sensitive data will be dealt with after the research project is completed.
Let’s look at UBC’s Behavioural Research Ethics Board (BREB) guidance notes for the Future Use of Data (subsection 8.6) as an example:
“Describe any known future use of the data beyond the conclusion of this research project, and indicate whether participant consent will be obtained in the current consent procedure or if the participant will be contacted later to obtain consent. Either possibility must be described in the consent process. If consent is to be obtained now, future use of data must also be described in full in the consent form. If consent will be obtained later, an amendment will be needed that includes the full details and updated consent form before the additional use of data begins.”
One of the future uses of sensitive data is making it openly accessible and available. As a part of some funding and publishing requirements, de-identified data and research findings may be required to be deposited in a repository. Participants must be informed when the data will be made available and accessible.
More language to inform participants on this topic is specified in UBC BREB subsection 8.6, “Access to Research Data”.

Assessing re-identification risk: “k-anonymity”
There are several ways to ensure that sensitive data does not lead to any risk of harm, such as re-identification. For example, a “statistical disclosure risk assessment” can be applied to evaluate the level of risk of potential identifiers.
One kind of risk assessment method is “k-anonymity”, which is a mathematical approach to demonstrating that a dataset has been de-identified. The concept of “k-anonymity” means that we shouldn’t be able to isolate less than “k” participants based on any combination of identifying variables. In other words, each participant’s record should “blend in” with a group of at least “k” records that share the same values of select indirect identifiers.
“k” is a numerical value that is determined by the researchers, which is commonly 3 or 5. For example, if k=5 then there needs to be at least 4 participants in the dataset with the same set of indirect characteristics to be unidentifiable.
Terminology when discussing k-anonymity:
- Equivalence class: the same values for a set of variables
- Sample unique: a unique combination of values for a set of variables, meaning that there are no “data twins”
Here is an example to illustrate this concept:
- Cases 1, 6, and 13 have an equivalence class with a k value of 3: this group of 3 records with the same values for a set of variables has a k value of 3, specifically.
- Case 14 is a sample unique with no “data twins” and has an equivalence class with a k value of 1: no other record shares this exact combination.
- The overall k value for this sample dataset is the equivalence class with the smallest k value, which is 1. This k value is not good because it does not offer sufficient de-identification. There is a record that is unique and can identify a participant.
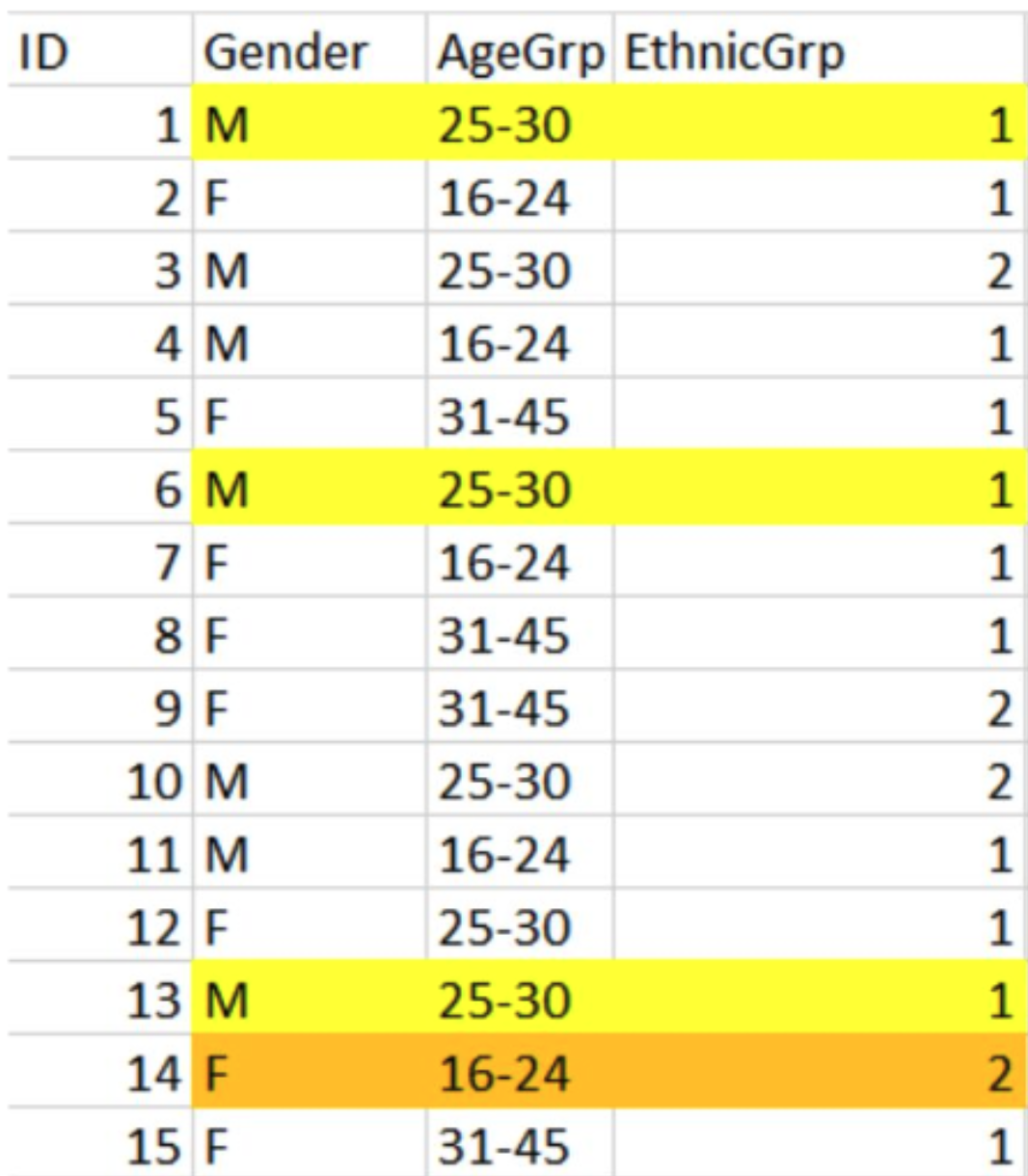
To achieve the determined k value (to prevent uniqueness that may lead to re-identification), there are some methods that can be used:
- Global data reduction: changes are made to variables across datasets, such as grouping responses into categories. This removes the risky variables of a dataset.
- Local suppression: individual cases or responses are deleted
Keep in mind that k-anonymity is not fail-proof because, regardless of how well you assess your dataset’s sensitivity, there is still the risk of re-identification.
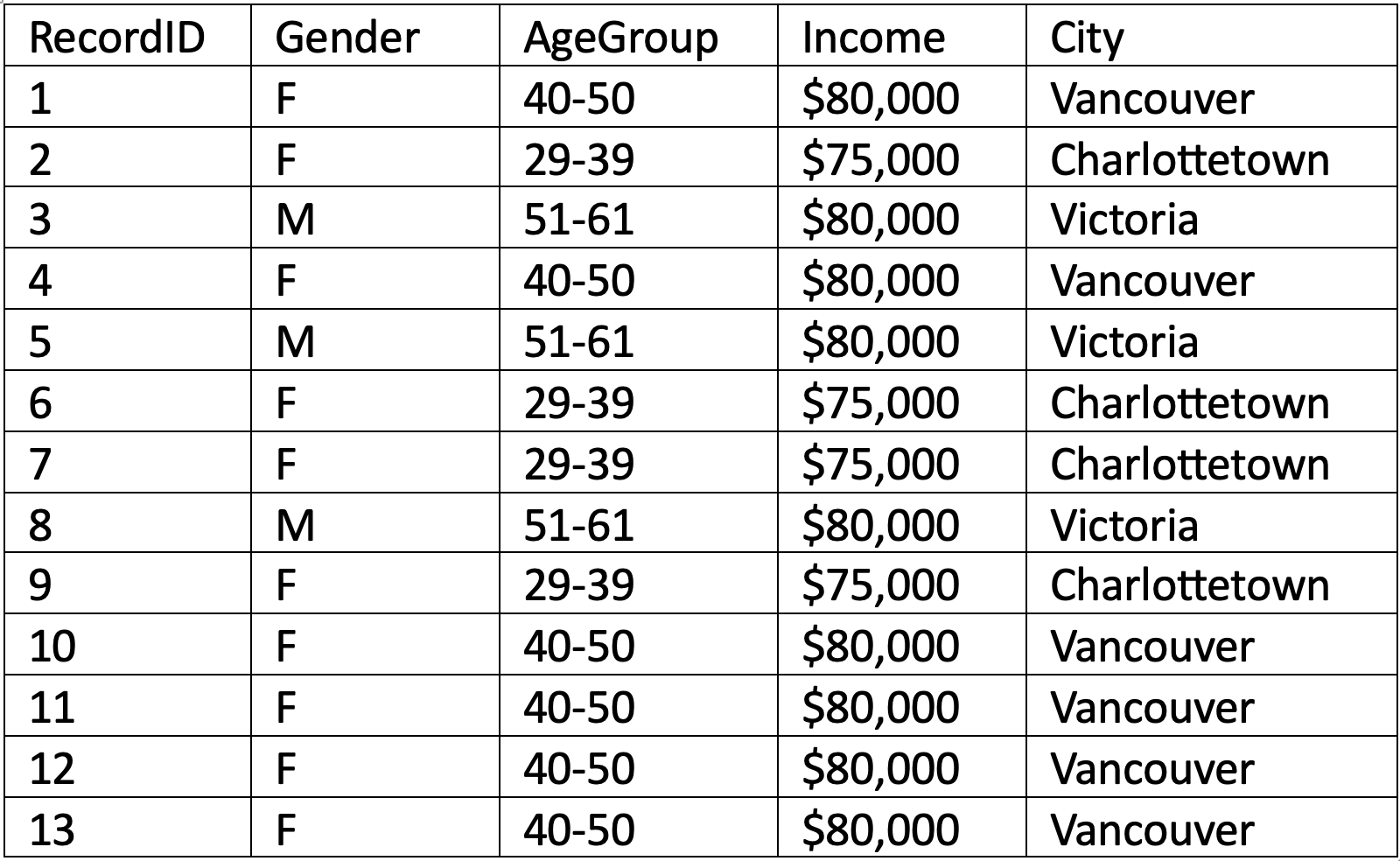
Exercise 2
Here is a sample of a dataset from a survey about living costs across Canada. From this dataset, answer these questions:
- Identify the equivalence classes and determine the k-anonymity for each class
- Determine the overall k-anonymity for the dataset. Is this a “good” k value?
Here’s a breakdown of what we covered: Sensitive data contains information that may lead to the identification of individuals, therefore it needs to be de-identified to protect against the risk and harm of possible unauthorized access and violations of privacy and confidentiality. Data is “sensitive” because it contains different kinds of identifying pieces of information: direct, indirect, non-identifying, and hidden. Assessing the level of risk for a dataset can be done using various statistical methods. A common method is determining the “k-anonymity”. How sensitive data is collected and dealt with must be addressed in your consent form for participants.
Congrats!
Hooray! You now have an introductory understanding of why research data undergoes de-identification, the different kinds of identifiers of a sensitive dataset, and one method of assessing the risk of a sensitive dataset.
Sources
- Rochlin, N. (2020, Oct. 14). Introduction to sensitive data & de-identification. https://osf.io/hv9pf/overview
- Rod, A. B. & Thompson, K. (2023). Chapter 13: Sensitive data: Practical and theoretical considerations. https://doi.org/10.5206/EKCH6181
- Thompson, K. (2023, Nov. 7). McGill data anonymization workshop series - 1. Reducing risk: An introduction to data anonymization. https://doi.org/10.5281/zenodo.10079239
- UBC Advanced Research Computing. Research information classification. https://arc.ubc.ca/security-privacy/research-information-classification
- UBC Office of Research Ethics. Writing behavioural ethics applications: Guidance notes, subsection 8.6 “future use of data”. https://researchethics.ubc.ca/behavioural-research-ethics/breb-guidance-notes/guidance-notes-behavioural-application
Need help?
Please reach out to research.data@ubc.ca for assistance with any of your research data questions.
Loading last updated date...